![[논문 리뷰] Stop Regressing: Classification for Value Functions in RL](/assets/img/260409/image_3.png)
[논문 리뷰] Stop Regressing: Classification for Value Functions in RL
작성자: 민예린
논문 정보
제목: Stop Regressing: Training Value Functions via Classification for Scalable Deep RL
저자: Jesse Farebrother, Jordi Orbay, Quan Vuong, Adrien Ali Taïga, Yevgen Chebotar, Ted Xiao, Alex Irpan, Sergey Levine, Pablo Samuel Castro, Aleksandra Faust, Aviral Kumar, Rishabh Agarwal
학회: arXiv Preprint
1. Introduction
Background
- 지도 학습에서는 AlexNet부터 Transformer까지, Classification 문제가 대규모 신경망 학습에 특히 잘 맞는다는 패턴이 반복되어 왔음
- Regression이 자연스러운 문제에서도 Classification으로 재정의하면 성능이 오르는 경우가 많음
- 핵심: Value-based RL은 주로 MSE Regression에 의존
- DQN, Actor-Critic 등은 연속 스칼라 타겟에 대해 MSE를 사용
- 이 방식은 대규모 네트워크(Transformer 등)로 확장할 때 성능이 정체되거나 오히려 하락하는 문제가 있음
→ 본 논문의 질문: “Regression 대신 Classification을 쓰면 RL에서도 지도학습 수준의 확장성을 확보할 수 있는가?”
Key Findings
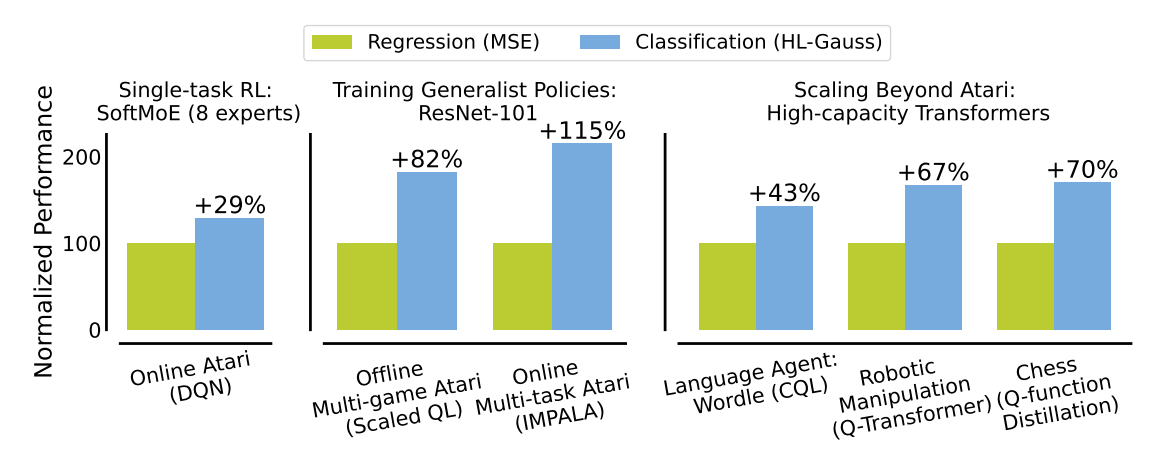
- HL-Gauss (Histogram Loss with Gaussian; Imani& White 2018)가 가장 효과적
- Atari 단일 작업 (SoftMoE): MSE 대비 ~30% 향상 (expert 수에 무관하게 일관적)
- Atari 다중 작업 (ResNet-101): 1.8~2.1배 성능
- Wordle 언어 에이전트: ~40% 향상
- Chess without Search: ~70% 향상 (AlphaZero w/ 400 MCTS에 근접)
- 로봇 조작 (Q-Transformer): 67% 향상 + 샘플 효율성 대폭 개선
- Classification 방식의 이점은 주로 아래 RL 고유의 문제를 완하하는 데서 비롯됨
- Noisy targets
- Non-stationarity
- Representation quality
→ 확률적 환경에서의 노이즈나, 타겟이 계속 변하는 경우 의미있음
2. Preliminaries and Background
Regression as Classification

-
Regression : x에 대한 y를 예측하고, MSE를 최소화
\[\min_\theta \sum_{i=1}^{N} (\hat{y}(x_i; \theta) - y_i)^2\] -
Regression as Classification : target value의 분포를 학습하고 분포의 통계치(ex. 기댓값)으로 $\hat{y}$ 을 구함
\[\min_\theta \sum_{i=1}^{N} \int_{\mathcal{Y}} p(y|x_i) \log(\hat{p}(y|x_i;\theta)) \, dy \tag{2.1}\]- 이를 위해 예측 분포를 m개의 bin 의 범주형 분포로 구성 ( [v_min, v_max] )하여 "어느 bin에 속할 확률이 높은지"를 맞추는 문제로 변환 (distributional problem)
3. Value-Based RL with Classification
Categorical Representation 방법
- TD 학습의 회귀 문제를 분류로 전환
- Q값과 TD 타겟 사이의 MSE 대신, 범주형 분포 사이의 Cross-Entropy를 최소화
Step 1. 네트워크 출력: m개의 로짓 → softmax → 확률 분포
- 네트워크는 스칼라 Q값 대신 m개의 logit을 출력하고, softmax로 각 bin의 확률을 계산
- 각 bin z는 Q 값의 후보 숫자이고, p는 해당 후보 숫자일 확률을 의미
Step 2. 대표 Q값 계산: 확률 분포의 기댓값(가중 평균)
- action을(argmax) 선택하기 위해 분포를 요약한 대표 Q 값 필요
- 모든 bin의 정보를 확률에 비례해서 반영하는 기댓값을 사용
Step 3. 타겟 분포 생성 + Cross-Entropy 학습
- Target 을 계산하고, 이를 bin 위의 확률 분포로 변환
- 네트워크의 예측 분포 / 타겟 분포 사이의 Cross Entropy 최소화
[\text{TD}_{\text{CE}}(\theta) = \mathbb{E}_{\mathcal{D}} \left[ -\sum_{i=1}^{m} p_i(S_t, A_t; \theta^-) \log \hat{p}_i(S_t, A_t; \theta) \right] \tag{3.1}]
👀 수치 예시: 5개의 bin 으로 이해하기
bin 위치: z = [-2, -1, 0, 1, 2]
Step 1. 네트워크가 상태 s에서 출력한 확률: p̂ = [0.1, 0.05, 0.15, 0.50, 0.20]
→ “Q값이 1일 확률이 50%로 가장 높다”
Step 2. Q값 복원 (기댓값)
-
Q = 0.1×(-2) + 0.05×(-1) + 0.15×(0) + 0.5×(1) + 0.2×(2) = 0.65
→ 이 값으로 argmax 해서 행동 선택 (기존 DQN과 동일)
Step 3. 벨만 타겟이 0.8이라면(가정), HL-Gauss로 타겟 분포 생성
-
p = [0, 0.02, 0.18, 0.60, 0.20]
→ p̂이 p에 가까워지도록 로짓을 업데이트
만약 MSE 였다면?
- loss = (0.65 - 0.8)² = 0.0225, gradient ∝ (0.65 - 0.8) = -0.15
- 만약 타겟이 갑자기 50으로 튀면 gradient = (0.65 - 50) = -49.35
- Cross-Entropy는 “이 bin 확률을 올려라/내려라”라는 신호일 뿐, 수치적 거리에 비례해서 흔들리지 않음
Constructing Categorical Distributions from Scalars
Scalar TD target 을 fixed bin 의 확률 분포로 projection 하는 3가지 방법
1. One-Hot
- 가장 가까운 bin 하나만 확률 1, 나머지는 0
-
bin 위치: z = [-2, -1, 0, 1, 2], 벨만 타겟이 0.8
→ p = [0 0 0 1 0]
-
- quantization error 가 크고, bellman 업데이트 반복 시 에러 누적됨
2. Two-Hot (Muzero 활용)
- target 값과 인접한 2개의 bin 에 선형 보간으로 확률 배분
-
bin 위치: z = [-2, -1, 0, 1, 2], 벨만 타겟이 0.8
→ p = [0 0 0.1 0.9 0]
-
- 클래스 간 순서 구조나 정보가 one hot보단 많지만, 충분하지 않음
3. HL-Gauss
- target 값을 평균으로 하는 gaussian 분포를 생성, 여러 bin에 확률을 분산
-
bin 위치: z = [-2, -1, 0, 1, 2], 벨만 타겟이 0.8
→ p = [0 0 0.1 0.7 0.2]
-
- 본 논문에서 사용하는 방법
Categorical Return Distribution 모델링 (C51)
공통점
- C51(Distributional RL 계열) 도 return 의 분포를 categorical 로 모델링
- Cross-Entropy 를 최소화하는 구조로 HL-Gauss 와 유사함
차이점
- Scalar target 을 변환하는 대신 미래 return의 분포 자체를 모델링 (Distributional RL)
- 본 논문: 대규모 모델 학습 시 MSE는 왜 불안정하고, Cross-Entropy는 왜 안정적인가 (최적화/확장성 관점)
-
HL-Gauss, Two-Hot과의 비교 대상으로 사용되며, 결과적으로 HL-Gauss가 C51보다 나은 경우가 많음
→ 단순히 CE 사용 여부보다, 어떤 target distribution을 사용하느냐와 그로 인해 형성되는 gradient 특성이 더 중요할 수 있음
4. Evaluating Classification Losses in RL
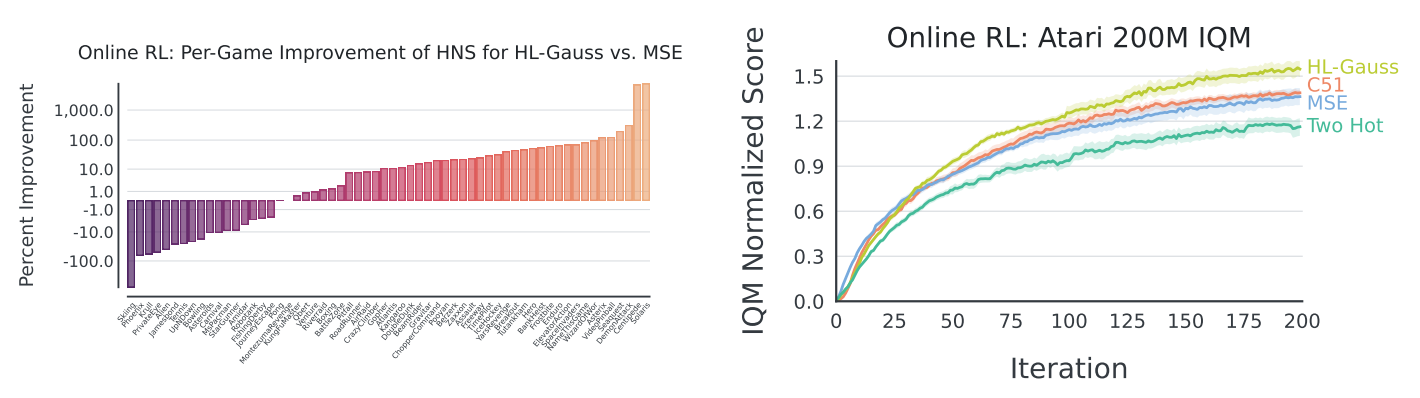
Single-Task RL on Atari Games
- DQN + Adam 으로 학습
- IQM (Interquartile mean) normalized scores로 평가
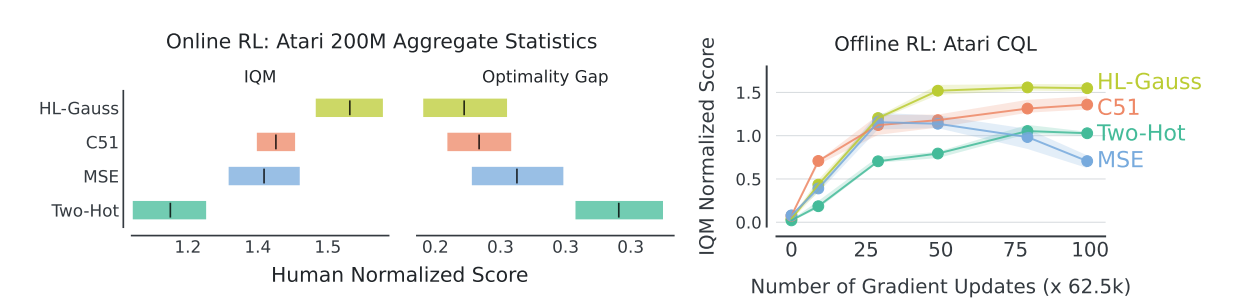
Online RL 결과 (왼쪽)
- IQM → 높을수록 좋음, Optimality Gap → 낮을수록 좋음
- HL-Gauss > C51 > MSE > Two-Hot
- HL-Gauss가 60개 게임 중 약 3/4에서 MSE를 이김, 절반에서 10% 이상 향상
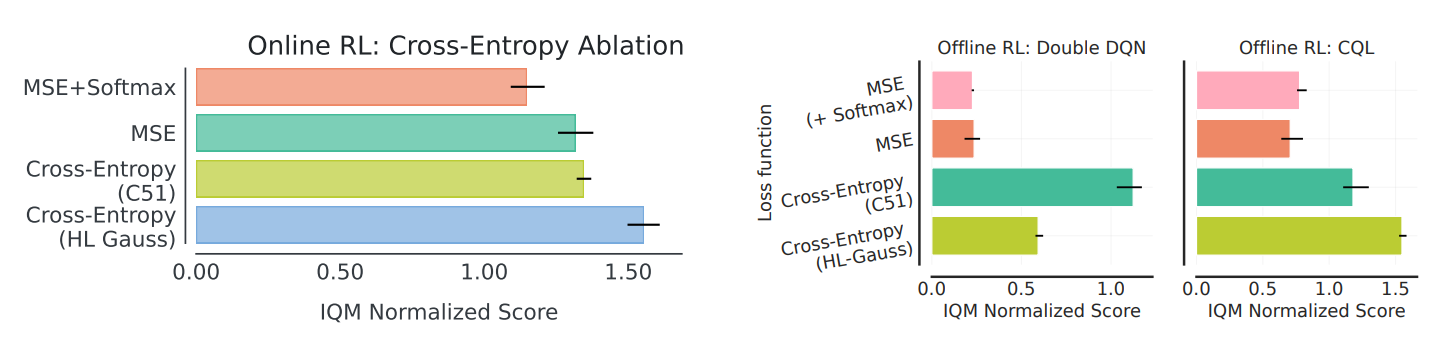
Offline RL 결과 (오른쪽)
- CQL 로 학습, DQN의 10% replay dataset 사용
- MSE : 후반으로 가면 성능 하락 발생
Scaling Value-based RL to Large Networks
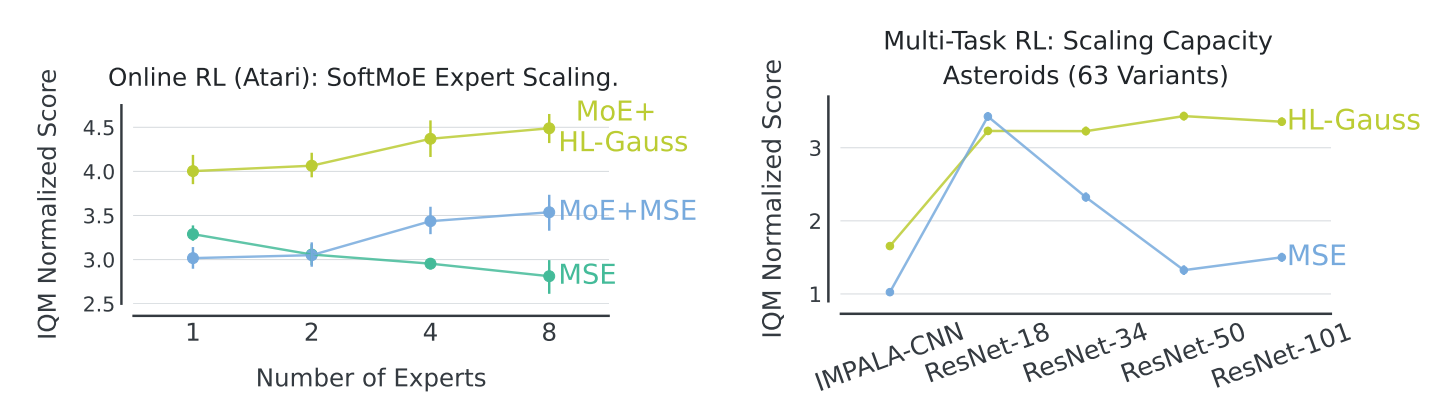
Scaling with Mixture-of-Experts (왼쪽)
- Impala 의 penultimate layer를 SoftMoE 모듈로 교체하고 expert 수를 {1,2,4,8}로 변화하여 실험
- penultimate layer : output layer 바로 앞에 있는 레이어로 feature representation 정보 존재
- HL-Gauss가 expert 수에 무관하게 MSE 대비 ~30% 일관된 향상
Training Generalist Policies with ResNets (오른쪽)
- MSE는 모델이 커질수록 성능이 심각하게 하락
Multi-game offline RL
- 40개 Atari 게임 동시 학습
- ResNet-{34, 50, 101}로 scaling
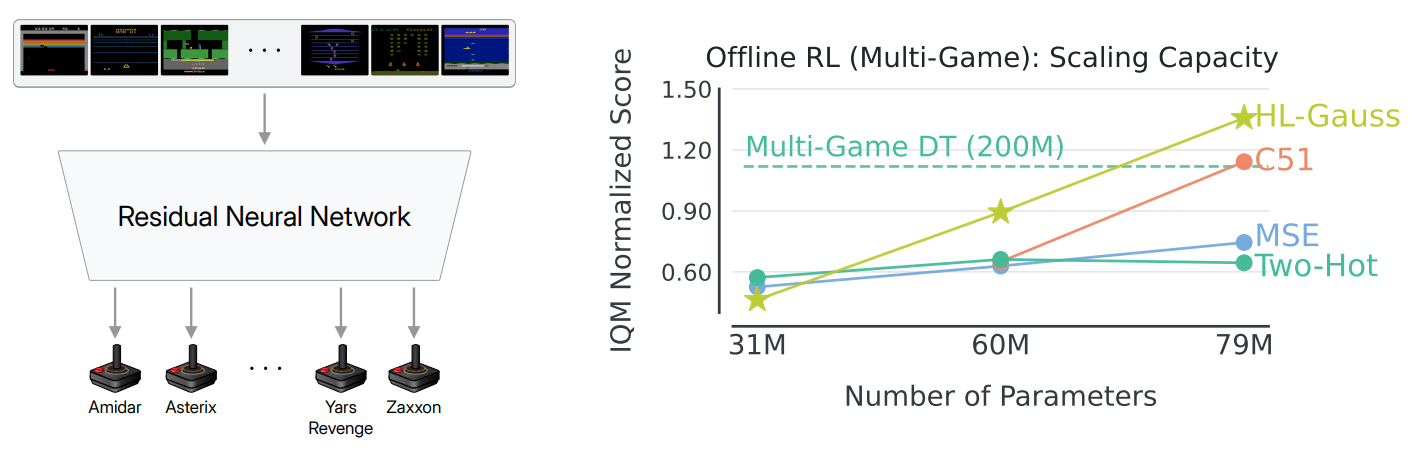
Value-Based RL with Transformers
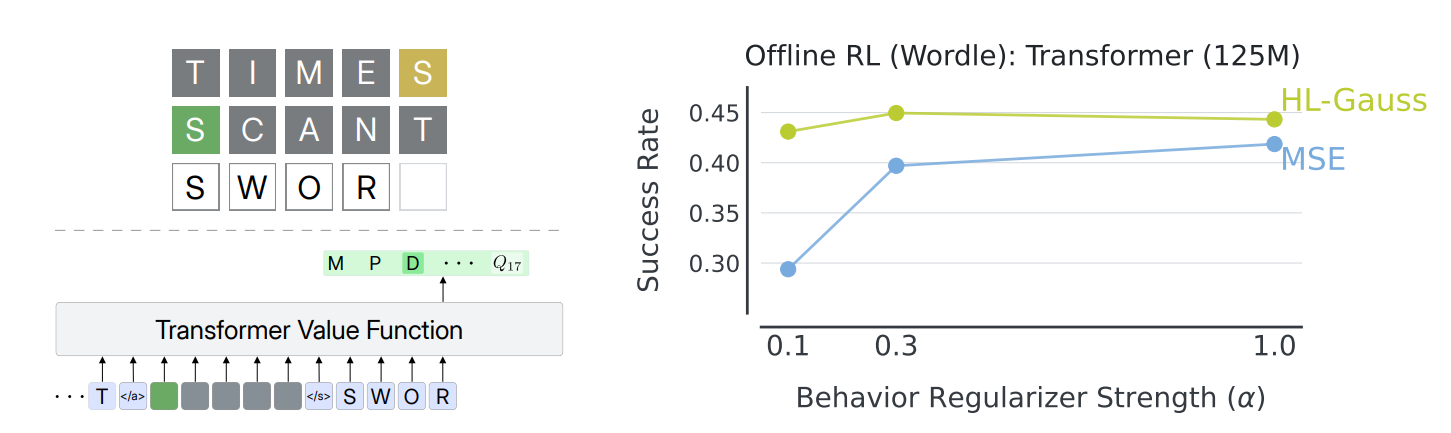
Language Agent: Wordle
- 125M 파라미터 GPT-like Transformer로 Q-network 구성
- Offline RL (DQN + CQL-style regularizer), 20K gradient steps
- HL-Gauss가 모든 CQL regularization 강도에서 MSE를 능가
- non-deterministic 텍스트 환경에서도 유효
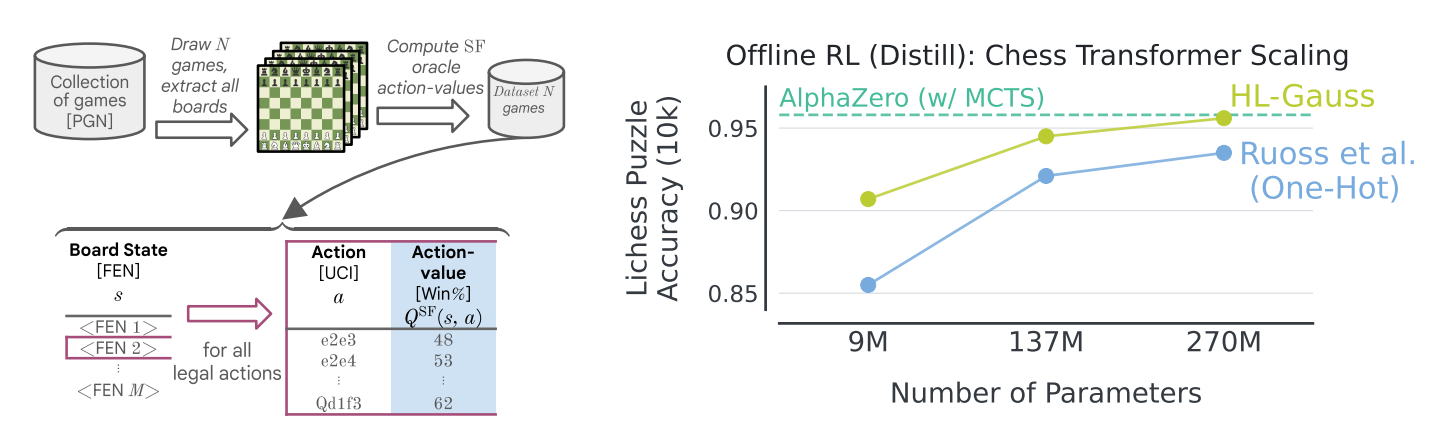
Grandmaster-level Chess without Search
- Stockfish 16의 action-value를 causal transformer로 distillation
- 10M 체스 게임, 15B 데이터 포인트
- 9M, 137M, 270M 파라미터 모델 비교 (HL-Gauss vs 1-Hot)
- MSE는 이미 1-Hot보다 성능이 낮아 비교에서 제외
- 270M 모델에서 HL-Gauss가 AlphaZero w/ 400 MCTS에 근접
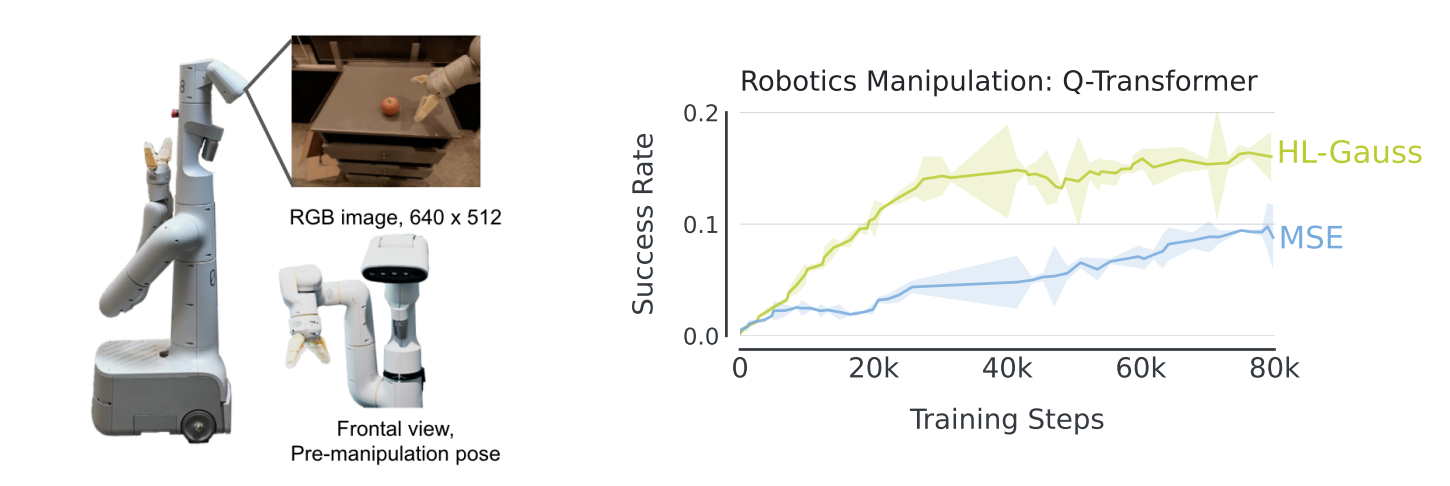
Generalist Robotic Manipulation with Offline Data
- 7-DoF manipulator / lift 17 different kitchen objects
- 500K 에피소드 (성공+실패), Q-Transformer 60M 파라미터
- HL-Gauss: MSE 대비 67% 높은 peak 성능 + 훨씬 빠른 학습
5. Why Does Classification Benefit RL?
Ablation Study
- Q-network 출력에 softmax를 씌우되 MSE로 학습 → 성능 향상 없음
- Cross-Entropy loss 자체가 핵심
What Challenges Does Classification Address in Value-Based RL?
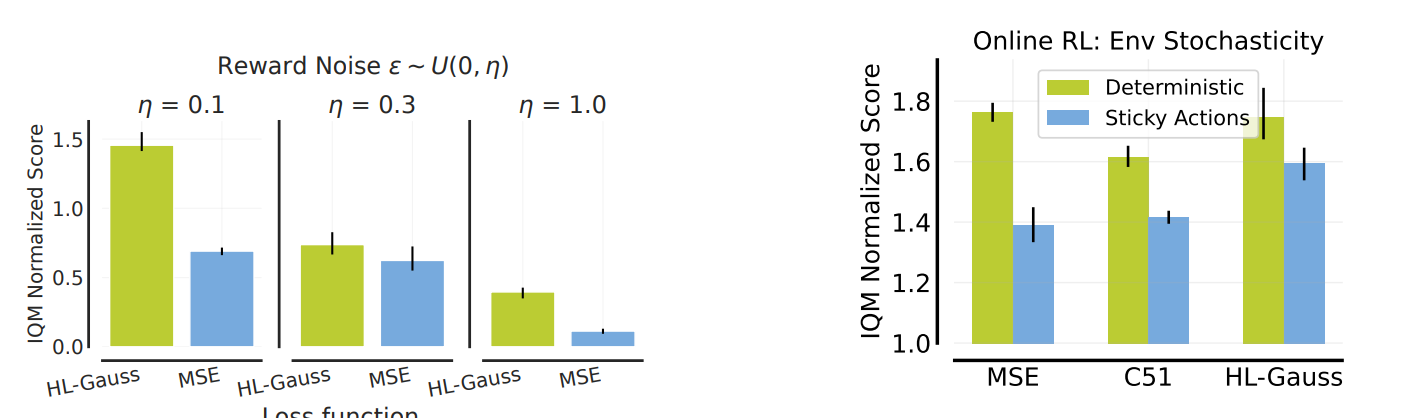
Noisy Target
- (왼쪽) Offline RL에서 보상에 노이즈 추가 (η ∈ {0.1, 0.3, 1.0})
- HL-Gauss: 노이즈 증가에도 성능이 완만하게 하락 vs MSE: 급격히 하락
- (오른쪽) Stochastic Dynamics
- Sticky actions(25% 확률로 이전 행동 반복, buffer에는 현재 행동 기록) on/off 비교
- Stochastic dynamics에서: HL-Gauss » MSE
- Deterministic dynamics에서: HL-Gauss ≈ MSE > C51
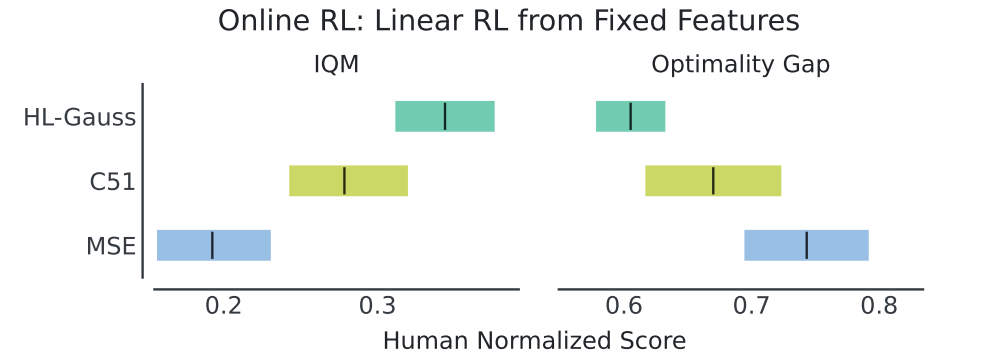
더 풍부한 Representation 학습
-
Linear Probing 실험: 200M frames 학습 후 penultimate features를 고정
→ single linear layer로 Q-function 재학습
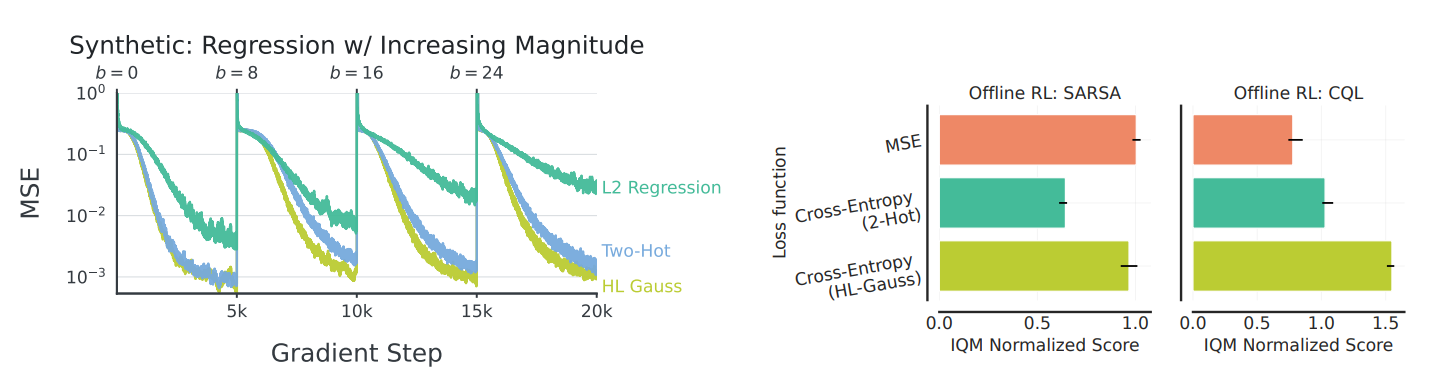
Non-Stationarity
- (왼쪽) Synthetic Setup (CIFAR10)
- target 값을 b ∈ {0, 8, 16, 24, 32}로 점진적 증가시켜서 non-stationary 데이터를 생성
- MSE : 수렴 속도가 느려짐
- HL-Gauss, Two-Hot: magnitude에 무관하게 일정한 수렴 속도 유지
- (오른쪽) Offline RL: Q-learning vs SARSA
-
SARSA (타겟이 고정 정책 기반 → non-stationarity 없음)에서는 HL-Gauss와 MSE의 격차가 거의 사라짐
→ classification의 이점 중 상당 부분이 non-stationarity 대응 능력에서 비롯
-
6. Conclusion
- Regression → Classification 전환이라는 단순한 변경으로 value-based RL 의 성능과 확장성이 대폭 개선됨
- Noisy target, Representation, Non-stationary 에 대한 대응력 향상
- 향후 과제 : pre-training, fine-tuning, continual-RL 등에서 효과 검증 필요