![[논문 리뷰] Steering Your Diffusion Policy with Latent Space Reinforcement Learning](/assets/img/250717/image_1.png)
[논문 리뷰] Steering Your Diffusion Policy with Latent Space Reinforcement Learning
작성자: 이민경
논문 정보
제목: Steering Your Diffusion Policy with Latent Space Reinforcement Learning
저자: Andrew Wagenmaker, Mitsuhiko Nakamoto, Yunchu Zhang, Seohong Park, Waleed Yagoub, Anusha Nagabandi, Abhishek Gupta, Sergey Levine, UC Berkeley.
학회: CoRL 2025
1. 배경
📍기존 Diffusion Policy의 문제점
- Diffusion Policy (BC Policy)는 풍부한 전문가 데모 데이터를 학습하는데, Diffusion 샘플링으로 멀티모달과 고품질의 action을 생성하는 장점이 있다. (데모 데이터만 있으면 바로 사용 가능함)
- 다만, 데모 데이터에 없는 새로운 환경이나 태스크가 주어지면 성능이 떨어지는 한계가 있다.
- 문제는 데모 데이터를 추가로 수집해야 된다는 건데.
- 데모 데이터 수집은 시간도 오래 걸리고 비용이 비싸다.
- 그래서 이를 스스로 개선하기 위해서는 RL 파인튜닝을 사용하기도 하는데
- 기존의 RL 파인튜닝의 경우 다음과 같은 문제점이 존재
- 역확산 T-step에 전부 backpropagation을 하기 때문에 메모리와 연산이 폭발하고, gradient vanish나 gradient explode 문제가 생긴다.
- 가중치 자체를 업데이트를 하게 되어 데모데이터에서 학습된 안정적이고 성공적인 action(behavior)가 흐려질 수 있다 (Prior 훼손)
- 가중치나 중간 activation 없이 배포된 API 모델에는 적용이 어렵다.
- 수백만 파라미터를 최적화 해야 돼서 실제 로봇 환경에는 적용하기 어렵다.
✅ 그럼 이 논문은 어떤 아이디어로 Diffusion Policy 문제를 해결하려고 하는가
- Diffusion(DDIM/Flow) 모델은 ‘상태 $s$ + 초기 노이즈 $\omega$ → action $a$’이 deterministic.
- 즉 노이즈 $\omega$만 바꿔도 action $a$이 달라진다.
- action $a$ 말고, 노이즈 $\omega$를 제어해 볼까?
⇒ DSRL은 Diffusion Policy를 어떻게 환경에 맞춰 적응(fine-tuning, 정책을 새 태스크에 맞추어 업데이트)하게 할 것인가를 개선한 방식. 다시말해, Diffusion policy를 재학습하지 않고도 RL을 통해 빠르고 안정적으로 fine-tuning 할 수 있게 하는 방안을 제안한 것
- DSRL 아이디어
- Latent-noise space $\mathcal{W}$를 새 action space로 보도록 MDP 재정의
- 고정된(frozen) diffusion network $\pi_{\mathrm{dp}}$ 를 환경의 일부로 편입시켜 back-propation 과정에서 제거
- 저차원인 latent-noise policy $\pi^{\mathcal{W}}$ 만 RL로 학습해서 노이즈 분포를 상태 별로 최적화
- Noise-Aliased DSRL로, 원래 action space critic $Q^{\mathcal{A}}$와 noise space critic $Q^{\mathcal{W}}$를 두어 offline data와 noise aliasing distillation을 활용해 탐색 샘플을 절감
- 결과적으로
- diffusion chain에 back-propagation 연산을 안하게 되어 메모리와 연산 비용 감소
- gradient vanish/explode 문제 해결
- 가중치를 고정하여 에이전트가 데모데이터에서 배운 능력을 그대로 유지하게 되어 prior을 보존
- 샘플 효율과 API 호환성 문제 역시 해결
DSRL은 diffusion policy를 재학습하지 않고, 입력 노이즈 분포만 RL로 학습해서 policy를 steer하여 기존 RL 파인튜닝의 계산 비용, 안정성 이슈, API 호환성, 샘플 효율성 문제들을 한번에 해결
⇒ 노이즈 $\omega$를 조향(steer)해서 로봇 정책을 안정적이고 빠르게 업그레이드!
2. 문제 정의
DSRL은 “Action space → Latent-Noise space로 교체”하는 아이디어로서 이를 통해 계산·안정성·샘플 효율성·API 호환성 등 여러 문제를 해결한다고 주장한다. 단, 이를 위해서는 Latent Noise space $\mathcal{W}$가 충분히 조정 가능하고(steerable) value-function이 정확히 학습된다는 전제가 동반되어야 한다.
⚙️ 문제정의
- 사전훈련된 diffusion policy $\pi_{\mathrm{dp}}$이 MDP 환경 $\mathcal{M} = (\mathcal{S}, \mathcal{A}, P, p_0, r, \gamma)$에서 파라미터에 손대지 않고 $\pi_{\mathrm{dp}}$의 action을 조정(steer)해서 환경 보상 $r$을 최대화하는 것
- 여기서 ‘steerable’ 가정
- $\pi_{\mathrm{dp}}$는 초기 노이즈 $\omega \in \mathcal{W}$ 에 따라 출력 action이 달라질 수 있어야 함
- 만약 어떤 $\omega$를 넣어도 같은 $a$가 나오면 steer 불가
- 우리는 임의의 상태 $\mathbf{s} \in\mathcal{S}$와 노이즈 $\omega \in \mathcal{W}$를 넣고 $\mathbf{a}=\pi^{\mathcal{W}}_{\mathrm{dp}}(\mathbf{s}, \omega)$ 를 샘플링할 수 있어야 함
- 그외 내부 가중치, 중간 denoising step, gradient 모두 접근할 수 없음
3. Diffusion Steering via Reinforcement Learning
✅ 논문에서 제안하는 방식: DSRL
DSRL은 네트워크를 건들이지 않고 입력 노이즈를 ‘조향(steering) 핸들’로 삼아 원하는 행동을 유도하는 접근 방식을 의미. 즉 노이즈 분포만 바꿔서 행동을 바꿔보자는 취지로 제안된 기법
베이스 동작으로는 사전학습된 diffusion policy $\pi_{\mathrm{dp}}$가 “$\omega \sim \mathcal{N}(0, I) \to \mathbf{a} = \pi^{\mathcal{W}}_{\mathrm{dp}}(\mathbf{s}, \omega)$”로 행동을 생성한다. 이렇게 하면 데모 데이터의 행동 분포를 그대로 재현하게 된다. 이때 가우시안 대신 다른 $\omega$를 넣으면 출력 행동 분포가 달라진다. 즉 행동을 바꾸기 위해서 가중치 대신 노이즈 분포를 조절해도 된다는 것을 알 수 있다.
3.1. Diffusion Steering as Latent-Noise Space Policy Optimization
- 상태 $s$와 초기 노이즈 $\omega$를 입력으로 받아 T-step denoising을 수행해 행동 $a$를 만드는데, 초기에는 가우시안에서만 $\omega$를 뽑았지만, 노이즈 분포를 재학습하는 adpataion 단계에서는 $\omega$를 바꾸면서 다른 행동을 출력
- 기존의 diffusion policy에서는 $\pi_{\mathrm{dp}}$ 자체를 ‘행동을 내는 정책’으로 보았지만, DSRL에서는 $\pi_{\mathrm{dp}}$를 state-noise → action으로 매핑하는 고정 디코더($\mathcal{W}\to\mathcal{A}$)로 재해석
- 따라서 에이전트가 실제로 학습·결정하는 것은 ‘어떤 노이즈 $\omega$를 넣을지’에 대한 노이즈 정책 $\pi^{\mathcal{W}}$이며, $\pi_{\mathrm{dp}}$는 학습 대상이 아닌 환경의 일부로 취급됨
이렇게 재해석된 내용을 토대로 기존 MDP 환경의 action space $\mathcal{A}$에서 noise space $\mathcal{W}$로 매핑하면 다음과 같이 정의할 수 있다. 여기서 기존의 MDP 환경은 $\mathcal{M}^{\mathcal{W}} := (\mathcal{S}, \mathcal{W}, P^{\mathcal{W}}, p_0, r^{\mathcal{W}}, \gamma)$ 로 변환되는데, 원래 MDP의 $(\mathcal{S}, \mathcal{A})$에서 $(\mathcal{S}, \mathcal{W})$로 매핑한 환경을 의미한다. (단순히 action space = noise space로의 매핑이기에, 기존의 RL 알고리즘을 그대로 적용할 수 있다는 장점 있음)
\[ P^{\mathcal{W}}(\cdot \mid \mathbf{s}, \mathbf{\omega}) := P(\cdot \mid \mathbf{s}, \pi^{\mathcal{W}}_{\mathrm{dp}}(\mathbf{s}, \mathbf{\omega})) \quad \mathrm{and} \quad r^{\mathcal{W}}(\mathbf{s}, \mathbf{\omega}) := r(\mathbf{s}, \pi^{\mathcal{W}}_{\mathrm{dp}}(\mathbf{s}, \mathbf{\omega})), \]
이를 통해 사전학습된 $\pi^{\mathcal{W}}_{\mathrm{dp}}$를 완전히 블랙박스로 취급하여, 학습과정에서 네트워크 파라미터와 중간 feature들에 접근할 필요가 없게 되어 학습시 효율성이 높아짐
- 정리하자면 DSRL은 다음과 같은 과정을 거친다.
- 상태 $s$를 관측하고
- 노이즈 정책 $\pi^{\mathcal{W}}$이 $\omega$ 를 선택
- 고정된 디코더 $\pi^{\mathcal{W}}_{\mathrm{dp}}$로 $\mathbf{a}=\pi^{\mathcal{W}}_{\mathrm{dp}}(\mathbf{s},\omega)$
- 환경을 실행하고 → 보상 $r$ 최적화 → actor-critic으로 $\pi^{\mathcal{W}}$를 업데이트
- DSRL의 연산 효율성을 살펴보면
- 기존 파인튜닝 과정에서는 $\pi_{\mathrm{dp}}$까지 gradient를 보내 T-step back-propagation을 해야 했고
- 따라서 메모리 사용 증가 & 시간 및 연산 증가 & gradient explode 등 다양한 문제가 야기되었는데
- action space를 noise space로 매핑한 DSRL 덕분에 $\pi^{\mathcal{W}}$만 학습하면 돼서 back-propgation 깊이도 훨씬 얕고, 그결과 연산량도 감소하게 되고, 리얼월드의 로봇에서도 학습할 수 있게 됨
기존의 연구들은 Action($a$)을 조정하기 위해 파라미터(가중치)를 수정했다면, DSRL은 가중치 수정 대신, 입력 노이즈($\omega$) 값을 바꾸는 방식으로 Diffusion policy를 steering하는 기법을 제안
3.2. Efficient DSRL with Noise Aliasing
Diffusion Policy의 직접적인 파라미터 재학습 없이 입력 노이즈($\omega$) 값의 수정 만으로 생성되는 행동($a$) 값을 바꿀 수 있는 DSRL은 온라인 학습 환경에서는 쉽게 사용이 가능하지만, 오프라인 환경에서의 학습은 어렵다.
- 우선 온라인 강화학습의 경우, 자체 rollout으로 ($s,\omega,r,s’$)를 수집할 수 있지만, 기존의 데이터셋을 활용해서 학습하는 오프라인 강화학습에서는 ($s,a,r,s’$) transition만 저장되어 있고, DSRL에서 중요한 $\omega$는 존재하지 않는다. 따라서 $Q^{\mathcal{W}}(s,\omega)$를 학습할 수가 없어서 기존 RL 알고리즘에 바로 적용할 수가 없다.
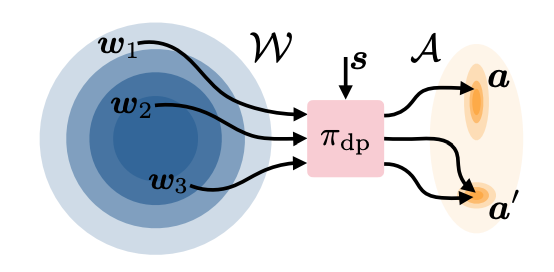
- 또한 Diffusion policy는 여러 $\omega$가 하나의 $a$에 매핑되는 many-to-one을 자주 보이는데, 이로 인해 만약 ($s,\omega$)별로 TD-target을 따로 주면, 같은 행동 $a$에 대해 서로 다른 값이 학습돼 critic 분산이 폭증한다.
(Noise Aliasing 문제)
- many-to-one mapping ($\omega\to a$)
- diffusion policy는 상태 $s$와 초기 노이즈 $\omega$를 받아 여러 단계의 denoising 후 행동 $a$를 출력한다. 하지만 데모 데이터가 좁은 분포라면, 여러 개의 서로 다른 $\omega_1,\omega_2,…$가 동일 행동 $a$로 깔끔하게 수렴할 수 있다.
- Actor-Critic의 한계
- 온라인 학습이라면 ($s,\omega$)를 실제로 선택한 횟수만큼 $Q(s,\omega)$가 업데이트 된다. 하지만 오프라인에서는 애초에 $\omega$가 주어진 데이터셋에 없어서 $Q(s,\omega)$를 감독할 샘플이 없다. 결국 같은 행동 $a$를 만드는 $\omega_N$들에 대해 value가 엉뚱하거나 critic이 아예 학습이 안되는 문제가 생긴다.
이 두가지 문제를 ‘action space에서 안정적으로 value를 학습한 뒤, 그 value를 noise space의 critic으로 distillaion’하는 Noised-Aliased DSRL를 고안했다.
- $Q^{\mathcal{A}}$가 이미 환경의 동역학과 보상을 학습하고, 그 결과 $Q^{\mathcal{W}}$가 사전 가치 지도를 얻게 되고, $\pi^{\mathcal{W}}$는 이 지도를 보고 높은 값이 있는 $\omega$ 근처만 탐색하면 되니까 랜덤으로 $\omega$를 찍어내는 비용이 감소하게 되고, $\omega$가 없는 오프라인 환경에서도 Q-distillation 덕분에 학습할 수 있게 됨 (distillation loss)

- 조금 더 쉽게 설명하자면
- 왜 여러 $\omega$ → 같은 $a$가 생기는가?
- 사전훈련된 diffusion policy가 집게로 병뚜껑을 쥐는 동작만 배웠을 때
- 초기 노이즈 $\omega$는 256차원 random seed인데, 병을 잡는 방식이 하나뿐이라면
- 이 256차원의 거대한 공간 안에서 수없이 많은 점($\omega_1,\omega_2,…$)이 똑같은 집게 토크 및 경로로 압축
- 기존의 actor-critic이 겪는 문제
- 온라인 학습의 경우
- 로봇이 $\omega_1$만 우연히 성공해도 $Q(s,\omega_1)$은 증가하는데
- $\omega_2, \omega_3$은 시도도 안했으니 $Q$-값이 0이고
- 사실 같은 행동인데 값이 다르게 저장되어 critic 분산이 증가하고 탐험이 증가하게 됨
- 오프라인 학습의 경우
- 데이터셋에 ($s,a,r$)만 있고 $\omega$가 없어서 $Q(s,\omega)$ 자체를 학습할 샘플이 없고 학습이 불가능
- 온라인 학습의 경우
- Noise-Aliased DSRL의 아이디어는
- 행동 $Q^{\mathcal{A}}(s,a)$ 로부터 학습
- 오프라인 데이터셋으로 ‘로봇이 집게를 잘 쥐면 +1’ 같은 value를 안정적으로 학습
- 노이즈 $Q^{\mathcal{W}}(s,\omega)$로 value 복사
- 랜덤으로 $\omega$를 뽑아서 $\pi^{\mathcal{W}}_{\mathrm{dp}}$ → $a’$ 를 얻음
- Loss func: $(Q^{\mathcal{W}}(s,\omega) - Q^{\mathcal{A}}(s,a’))^2$
- $a’$가 좋으면 그 $a’$를 만드는 모든 $\omega_1,\omega_2,…$가 한번에 높은 값을 갖음
- $\pi^{\mathcal{W}}$ 업데이트
- 이제 critic이 어느 $\omega$가 좋은지 지도를 갖췄으므로
- $\pi^{\mathcal{W}}$는 그 근처만 탐색하면 돼서 샘플 효율성 증가
- 행동 $Q^{\mathcal{A}}(s,a)$ 로부터 학습
- 다시 예시를 들어보자면
- 병뚜껑 동작으로 +1 보상을 준 데이터셋이 있다면,
- $Q^{\mathcal{A}}$ 는 “뚜껑 잡기 == +1” 을 학습
- $\omega_2, \omega_3$을 넣어도 뚜껑 잡기가 나오면 $Q^{\mathcal{W}}(s,\omega_2) = Q^{\mathcal{W}}(s,\omega_3) = +1$ 로 즉시 전파되고
- $\pi^{\mathcal{W}}$ 는 이들의 고점 ($\omega_2, \omega_3$) 근처만 빨리 찾으면 되니까
- 무의미한 노이즈를 시도할 필요가 없게 되어
- 탐험량을 최소화할 수 있음
- 정리하면 DSRL-NA는
- 오프라인 데이터셋에 노이즈 $\omega$ 가 기록돼 있지 않은 관측 불가 문제와
- 여러 $\omega$ → 하나의 $a$로 매핑되는 가치 분산 문제인 noise aliasing 문제를
- 해결하기 위해 고안된 방식
- 왜 여러 $\omega$ → 같은 $a$가 생기는가?
DSRL-NA를 통해
- 오프라인 환경에서도 $\omega$ 없는 데이터셋을 활용해서 학습할 수 있게 되었고
- 같은 행동은 같은 가치를 지니는 구조로 탐험 횟수가 감소하여 샘플 효율성이 증가했으며
- $\pi_{\mathrm{dp}}$가 in-distribution action만 생성해서 OOD 걱정 없이 value를 평가할 수 있음
⇒ “같은 행동에는 같은 가치를 주자”는 아이디어를 noise space critic distillation 방식으로 구현해 기존의 actor critic이 놓친 diffusion의 구조적 이점을 활용한듯.
4. 실험
모든 실험은 사전학습된 diffusion policy $\pi_{\mathrm{dp}}$를 완전히 고정하고, 노이즈 actor $\pi^{\mathcal{W}}$와 critic $Q^{\mathcal{W}}$만 학습 대상으로 두는 actor-critic 기반 DSRL 기본 방식으로 수행함
4.1. DSRL Enables Efficient Online Adaptation of Diffusion Policies
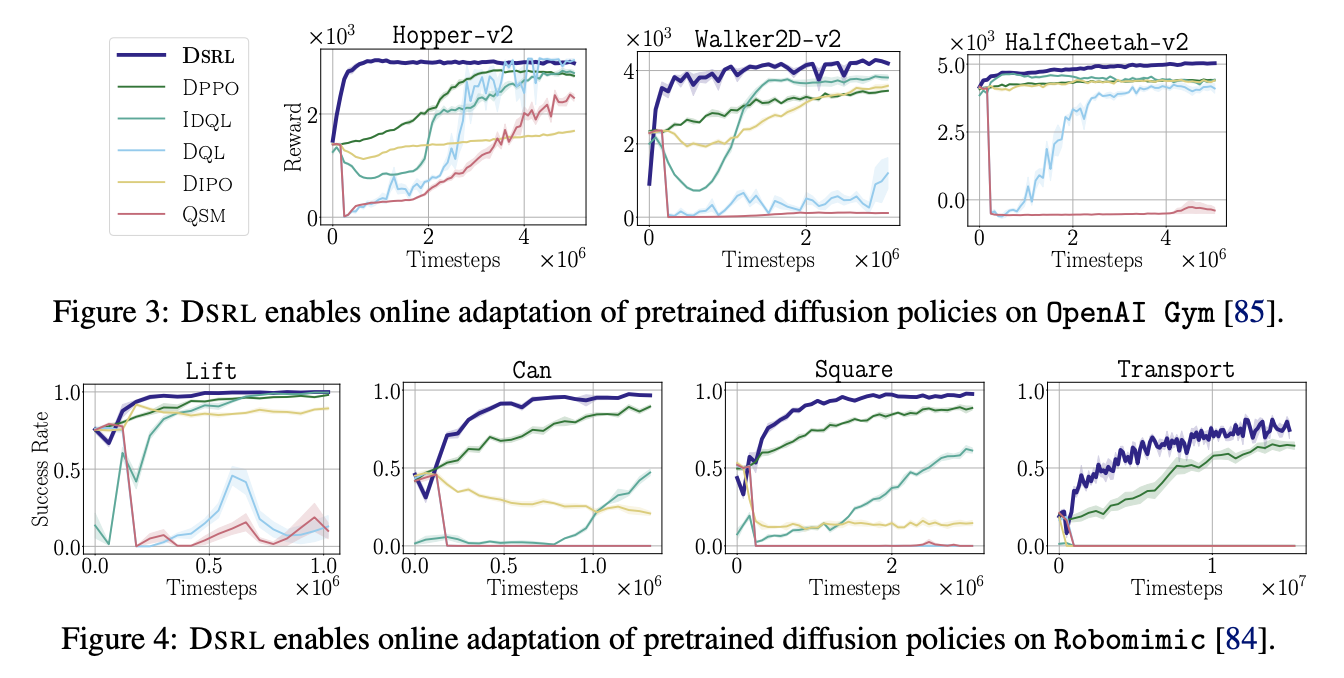

- OpenAI Gym 태스크 전부 DSRL이 우수한 결과를 보였고
- Robomimic의 4가지 태스크에서 역시 높은 성공률을 보임
- 즉 사전학습된 BC policy $\pi_{\mathrm{dp}}$ 를 고정하고 latent-noise policy $\pi^{\mathcal{W}}$만 학습한 online learning에서 효율성과 안정성 모두를 달성함
4.2. DSRL Enables Efficient Offline Adaptation of Diffusion Policies
- offline learning only 실험으로 ($s, a, r, s’$) 데이터셋으로 구성된 OGBench 벤치마크 환경에서 실험
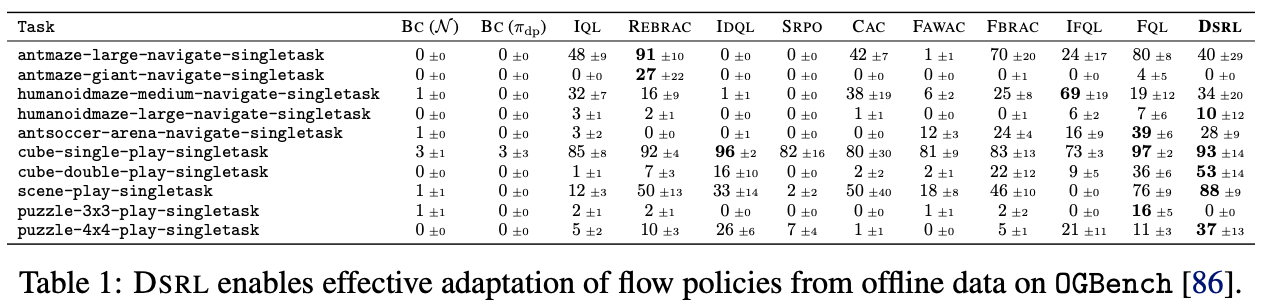
- offline dataset에 latent-noise가 없어도 Q-distillation으로 value 전파가 가능하다는 것을 보여주는 실험
- 오프라인 데이터셋으로 학습한 BC policy $\pi_{\mathrm{dp}}$ 를 고정하고,
- 같은 데이터셋에 DSRL-Noise Aliasing을 적용해서 실험
- BC($\pi_{\mathrm{dp}}$)와 비교했을 때, 대부분 두 자릿수 성능을 선보임.
- 즉 Noise-Aliasing distillation으로 ($s,a,r,s’$) 데이터셋만으로도 $\omega$-critic이 dynamics 정보를 획득할 수 있었고, $\pi_{\mathrm{dp}}$가 in-distribution action만 생성하므로 CQL 패널티 없이도 안정적임
- 그런데 다른 SOTA들과 비교해보면, DSRL이 드라마틱하게 좋다고는 말하기 어렵지 않나?
4.3. DSRL Enables Efficient Offline-to-Online Adaptation of Diffusion Policies
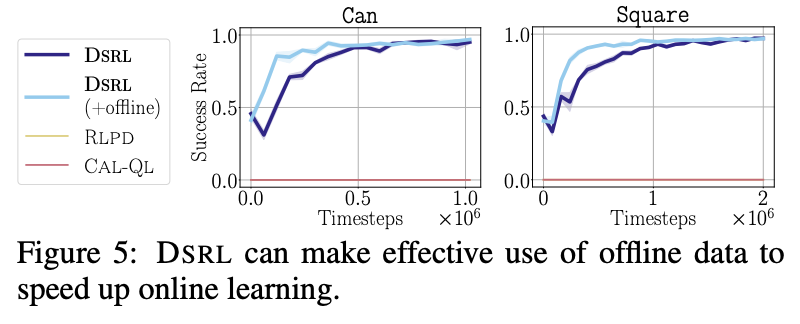
- online에서 빠른 bootstrap을 해서 실제 로봇 실험 전에 warm-start 하는 시나리오로 실험을 진행했는데
- 결과를 보면 offline+online DSRL이 초기에 빠른 상승을 보이는 것을 알 수 있음
- 즉 Noise-Aliasing distillation이 offline 정보인 value function을 online 학습으로 자연스럽게 전이하면서, 별도의 phase 전환이나 hyperparameter 재조정이 필요없어서, 단일 루프로 처리되며 속도가 빨라진듯
4.4. Adapting Real-World Single- and Multi-Task Robot Policies with DSRL
- $\pi_{\mathrm{dp}}$ rollout buffer 초기화
- single-task 10회, multk-task 20회 base policy를 실행해서 ($s,a,r,s’$) 수집
- 온라인 RL
- DSRL + SAC로 $\pi_{\mathrm{dp}}$ 고정하고, noise actor $\pi^{\mathcal{W}}$ 만 업데이트
- 베이스라인 모델
- RLPD : 실제 로봇에서 높은 성능을 보인 prior-policy distillation 방법
- RLPD + human interventions : 사람 개입으로 그리퍼 위치 보정
- 보상
- 0~1 sparce (성공 1, 실패 0)
- DSRL steering of single-task diffusion policy.
- Franka Panda 로봇팔(6-DoF) : 큐브를 집어 볼 속에 놓는 실험

- 10회 데모로 학습한 $\pi_{\mathrm{dp}}$ → DSRL 40 episode만에 성공률 거의 100% 상승
- 사람의 개입 없이 & $\pi_{\mathrm{dp}}$ 파인튜닝 대비, 9/10으로 높은 성공률
- DSRL on multi-task diffusion policy.

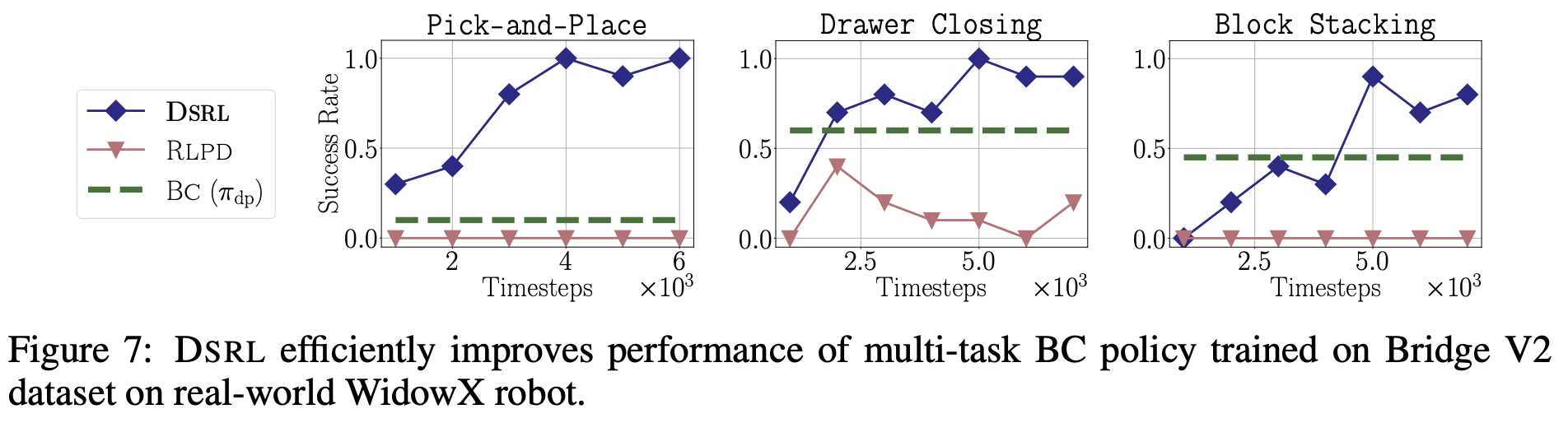
- DSRL이 BC와 RLPD보다 샘플 효율성이 좋고, 범용성이 뛰어나다는 것을 보여줌
- prior-policy distillation 방법인 RLPD보다도 우수할 수 있었던 이유는
- RLPD의 경우 diffusion policy의 파라미터를 파인튜닝했고 DSRL의 경우 해당 파라미터는 고정하고 저차원의 $\omega$-actor만 학습함
- 그 결과 RLPD는 gradient vanishing/explode 문제가 발생하지만, DSRL은 학습 분산이 크게 감소하여 안정적이고 높은 재현성을 보임
- 또한 RLPD는 가중치 파인튜닝 과정으로 인해 초기 행동 분포가 불안정한데, DSRL은 고정된 $\pi_{\mathrm{dp}}$가 이미 trajectory 내 행동을 보장하기에 sparse reward에서도 빠른 탐색이 가능함
4.5. Steering Pretrained Generalist Robot Policies with DSRL
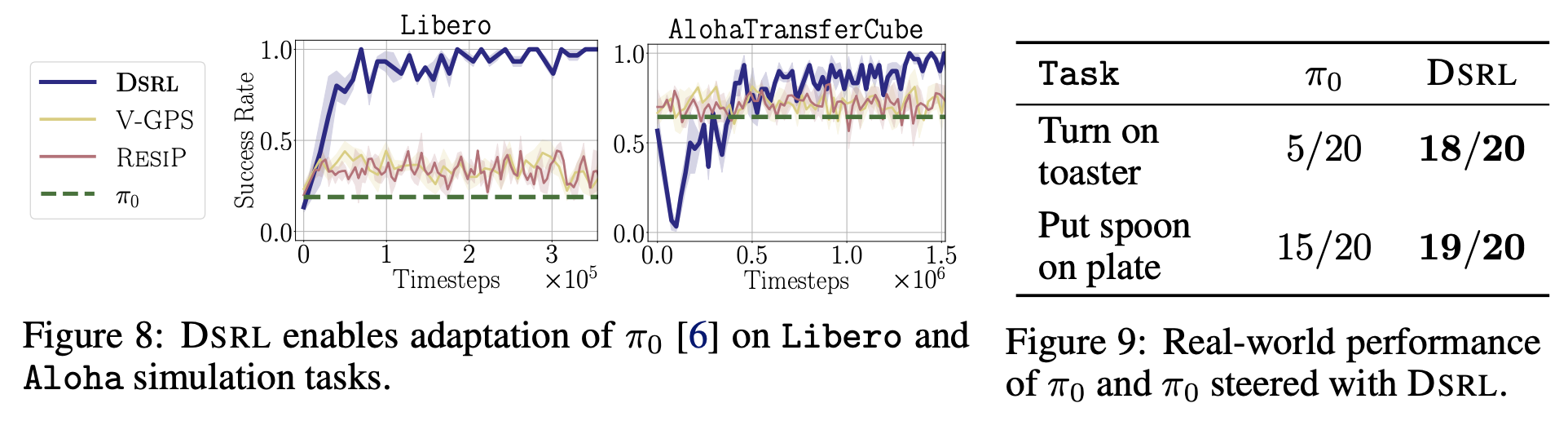
- $\pi_0$ 모델의 경우 (https://www.physicalintelligence.company/blog/pi0)
- 3.3B 파라미터로 구성되어있고, VLM backbone + flow-based action head 구조이고, 32D low-level joint x 50-step chunk → 1600D action vector를 만드는 구조
- 거대 파라미터로 구성되어 있어서 GPU 파인튜닝 비용이 많이 들고, 불안정함. 도한 초고차원의 action으로 기존 RL이 gradient를 흘려보내기 어려움
- DSRL을 적용한 경우
- $\pi_{\mathrm{dp}}$ 완전 동결하고, 저차원 noise actor $\pi^{\mathcal{W}}$ ($\approx$ 100K 파라미터)로 구성된 actor-critic 구조
- backpropagation 깊이가 1이라서 메모리와 연산비용이 작고, $\pi_{\mathrm{dp}}$가 이미 prior을 보유하고 있어서 sparse reward 환경에서도 탐험 잘함
- 그림 8의 실험은 Libero manipulation benchmark 환경과 AlohaTransferCube 환경에서 수행
- Libero-90 suite Pick-and-Place (한 팔, 고주파 제어, sparse reward)
- AlohaTransferCube (양 팔, long horizon, 정밀 그립)
- 그림 9의 Franka Panda 실험은
- 토스트 레버 켜기와 스푼을 접시에 올리기 두가지로 진행
- DSRL만 높은 성공률을 보인 이유는
- noise space가 action space보다 저차원이라 critic variance가 낮았고
- 사전학습된 $\pi_{\mathrm{dp}}$가 모션 prior을 보장해 의미있는 영역에서만 탐험을 수행할 수 있었음
4.6. [Ablation Study] Understanding Diffusion Steering
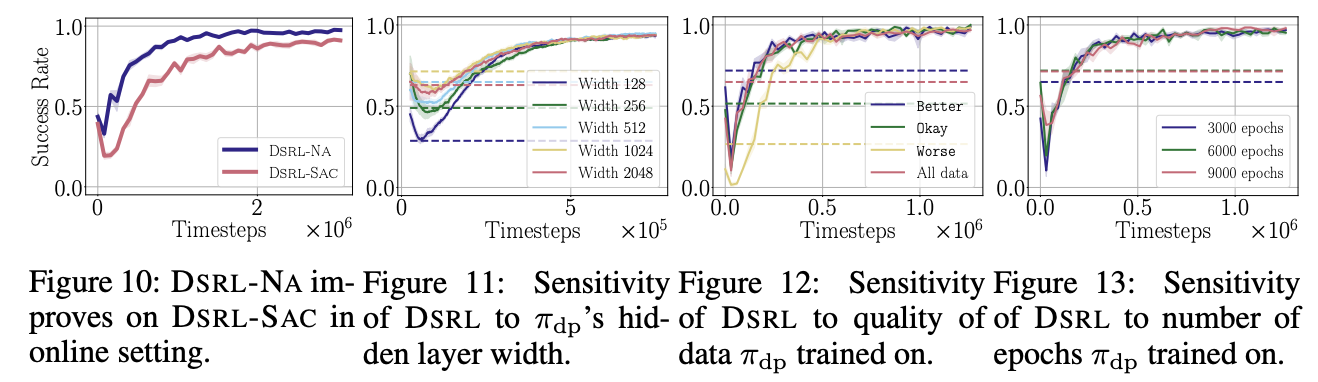
- Noise-Aliased DSRL 유무
- Noise-Aliased DSRL가 DSRL-SAC보다 성공률이 높음
- Noise-Aliased DSRL의 Q-distillation이 $\omega$-critic variance 낮추고
- 초기 value를 빠르게 채워 샘플 효율이 높음
- $\pi_{\mathrm{dp}}$ 모델 크기
- $\pi_{\mathrm{dp}}$ 초기 성능은 너비에 따라 0.3 ~ 0.55로 다름
- 큰 네트워크일 수록 잠재적 행동 다양성을 더 잘 포착해 steerable이 오히려 좋아질 수 있음
- 훈련 데이터 품질
- $\pi_{\mathrm{dp}}$ 자체 성능은 품질에 비례
- $\pi_{\mathrm{dp}}$가 ‘태스크 해결 행동’이 조금이라도 섞여 있으면, 품질이 낮아도 DSRL이 빠르게 성능 끌어올림
- $\pi_{\mathrm{dp}}$ 훈련 epoch 수
- $\pi_{\mathrm{dp}}$가 훈련 데이터에 과적합 되어도 noise-actor는 새로운 보상 신호만으로 조정 가능
- 정리해보면 - Noise-Aliased DSRL가 성능이 가장 좋고, 모델 크기나 데이터 품질, 과적합 전부 달라도 $\pi_{\mathrm{dp}}$가 멀티모달 noise → action으로 매핑만 하면 성능에는 문제 없음 - 따라서 실제 로봇에 모델 올린 뒤, 기존 데모와 환경이나 태스크가 조금 달라졌다면, $\pi_{\mathrm{dp}}$를 재학습 하는 대신 DSRL을 돌리는게 훨씬 가성비 좋음
- $\pi_{\mathrm{dp}}$가 훈련 데이터에 과적합 되어도 noise-actor는 새로운 보상 신호만으로 조정 가능
5. 정리
DSRL이 adaptation 과정에서 diffusion policy를 RL로 빠르고 안정적으로 개선할 길을 열었다.
- 기존 파인튜닝 방식의 한계를 noise-steering 방식으로 해결했고, 이는 로봇 policy를 blackbox로 간주해도 성능을 튜닝할 수 있다는 가능성과 API만 공개된 대규모 모델도 현장 적응을 자동화할 수 있다는 가능성을 보여줌
논문의 한계
- steerable reward 없음
- $\pi_{\mathrm{dp}}$의 행동 분포가 너무 좁으면, noise $\omega$ 바꿔도 효과 없음
- 탐험의 범위가 $\pi_{\mathrm{dp}}$ 능력
- $\pi_{\mathrm{dp}}$가 본 적 없는 새로운 태스크/환경에서는 도달 어려움
- RL에 의존
- 보상설게, 환경 리셋, 온라인 rollout 필요
- 개선량 사전 예측 불가
- 주어진 $\pi_{\mathrm{dp}}$가 어느정도까지 좋아질지 이론적 상한선이 없음