![[논문 리뷰] Reference Grounded Skill Discovery](/assets/img/251016/image_1.png)
[논문 리뷰] Reference Grounded Skill Discovery
작성자: 이민경
논문 정보
제목: Reference Grounded Skill Discovery
저자: Seungeun Rho, Aaron Trinh, Danfei Xu, Sehoon Ha, Georgia Institute of Technology.
학회: ICLR 2026
에이전트의 자유도(DoF)가 증가할 수록 탐색 공간(exploration space)이 기하급수적으로 커지는데, 이로 인해 의미있는 행동을 발견하기가 어려워진다. 실제로 유용한 스킬(skill)의 범위는 상대적으로 제한적이기에, 단순 무작위 탐색으로는 구조화되지 않고, 무의미한 움직임이 생성되는 이슈가 있다.
이 문제를 해결하기 위해 논문에서는 참조데이터(reference data)를 활용해 latent space를 semantic적으로 의미있게 grounding하는 접근인 Reference Grounded Skill Discovery (RGSD)를 제안하여, 고차원 시스템(359-차원의 obs, 69-차원의 action space를 가진 SMPL humanoid)에서도 다양하고 의미있는 스킬들을 발견할 수 있도록 한다.
즉, 저차원 환경만 다룬 기존 연구들과는 다르게 논문은 고차원 환경에서도 구조화된 스킬을 발견할 수 있게 하는 RGSD를 제안한다.
Introduction
Background
- Unsupervised skill discovery(USD)의 궁극적인 목표는 “재사용이 가능한 skill set을 획득해서 임의의 downstream tasks에 적용하는 것”으로 이를 위해 skill set은 다음과 같은 두가지 사항을 만족해야 한다.
- Diversity
- 가능한 다양한 다운스트림 태스크들의 분포를 폭넓게 커버할 수 있도록 충분히 다양해야 한다
- Semantic Meaningfulness
- 다운스트림 태스크들이 보통 semantic terms로 정의되기 때문에 스킬이 단순한 행동이 아닌 의미있게 해석될 수 있어야 한다
- Diversity
- 기존 연구들은 두 가지 요건을 만족하는 스킬을 학습하는데 성공했지만, 상대적으로 저차원 자유도에서의 실험이었고, 여전히 고차원 자유도 환경으로 USD를 확장하는 것은 챌린지로 남아있다.
- Why? 자유도가 증가할 수록 탐색 공간은 기하급수적으로 커지는데, **semantically meaningfulness 매니폴드는 상대적으로 작고. 이러한 불일치로 고차원 자유도에서의 skill discovery가 어렵다
- 따라서 논문에서는 skill discovery를 의미있는 매니폴드 내에서 grounding하는 메커니즘이 필요하다는 아이디어로 Reference Grounded Skill Discovery(RGSD)를 제안한다
Key Insight
- Reference Grounded Skill Discovery(RGSD)는 고차원 자유도 스킬 발견에서 발생하는 차원의 저주(curse of dimensionality)를 다루기 위해, semantic적으로 의미있는 스킬 잠재 공간을 사전에 구성하고 탐색을 이 공간 내로 제한하는 메커니즘,
- 방대한 고차원 공간에서 쉽게 발생하는 의미없는 행동들을 해결하기 위해, 잠재공간을 의미있게 구조화하여 에이전트의 탐색이 유용한 스킬 매니폴드에 집중되도록 유도한다
- 이때 RGSD는 DIAYN을 기반으로 구현되었는데 탐색을 하기 전에 참조 데이터를 활용해 잠재 스킬 공간을 먼저 grounding한다.
- Reference trajectory를 contrastive learning으로 처리해 unit hypersphere 위에 임베딩하는데. 이때 각 참조 행동들이 고유한 방향으로 매핑되어 잠재 공간이 semantic적으로 의미있는 매니폴드로 구조화된다. 이 grounding 단계가 이후 탐색을 제약하여 무작위적이고 비구조화된 움직임을 방지한다.
- 미리 구조화된 잠재공간을 활용해 참조 스킬을 모방하고 동시에 semantic적으로 관련된 새로운 행동들(behaviors)을 발견한다.
- 이 두 과정이 동시에 진행되고 결과적으로 RGSD가 참조데이터에 존재하는 모션을 재현하고 기존 behaviors의 coherent variations로서 새로운 스킬을 발견하게 된다
DIAYN (Diversity is All You Need)
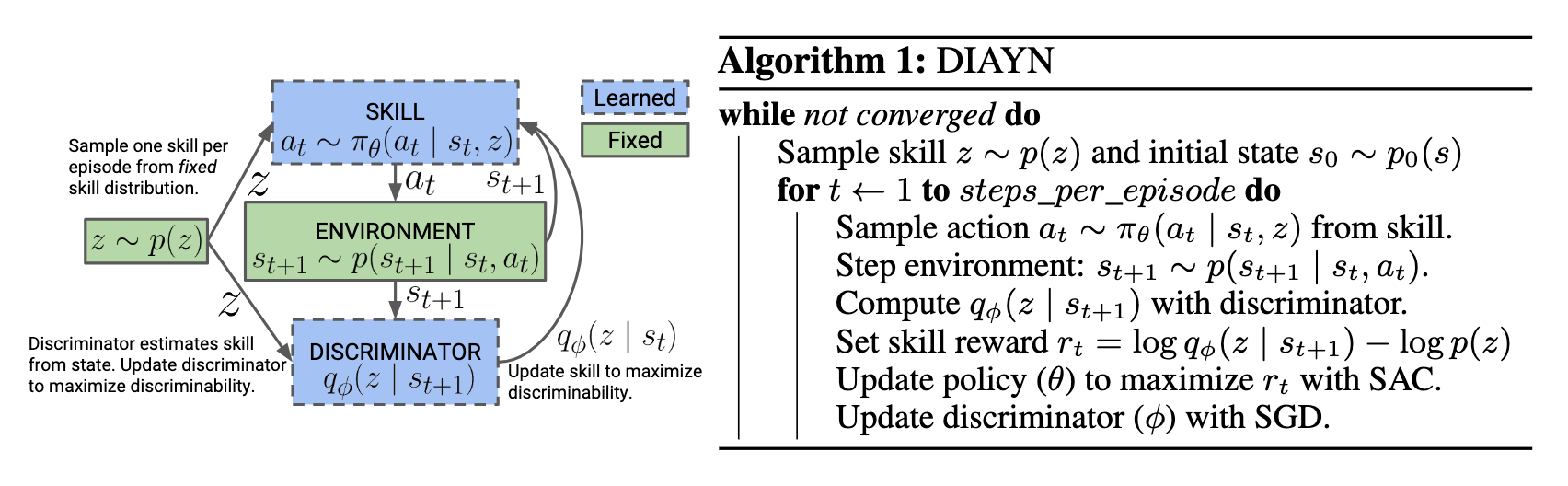
- https://sites.google.com/view/diayn/
- DIAYN은 리워드 없이 Unsupervised로 유용한 스킬을 학습하는 방법을 제안한 연구로, Mutual Information objective를 최대화하고, Maximum entropy policy를 사용해 에이전트가 환경을 탐색하며 걷고, 뛰는 등 다양한 스킬을 자율적으로 발견하도록 한다
- DIAYN는 sparse reward 환경의 탐색, long horizon task의 hierarchical RL, human feedback 최소화, 리워드 설계 어려움 극복 등에 유용하고, USD가 에이전트가 배울 수 있는 태스크의 범위를 파악하는데 도움이 됨.
Preliminaries
Reward-free MDP, $M := {\mathcal{S},\mathcal{A},\mathcal{P},\rho_0, \gamma}$
- Skill discovery의 목적은 특정 태스크에 대한 보상을 최적화하는 것이 아니라 재사용이 가능한 스킬을 자율적으로 학습하는 것으로
- Reward-free MDP의 목적은 잠재 스킬 벡터 $z$를 skill-conditioned policy $\pi_\theta(\cdot \mid s,z)$가 방문한 상태 $s$와 연관짓는 것, 즉 다른 $z$가 다른 distinct behaviors를 유도하도록 학습하는 것이다
- 보통 $z$ 는 고정된 prior $p(z)$ 에서 에피소드 시작 시 샘플링되고, 에피소드 내내 유지됨. 정책이 $z$ 에 따라 일관된 행동을 생성하도록 유도함
Mutual Information (MI) based Objective Function
-
스킬 $z$ 와 방문한 상태 $s$ 간의 MI 를 최대화
\[\mathcal{I}(s;z) = \mathcal{H}(s) - \mathcal{H}(s\mid z) = \mathcal{H}(z) - \mathcal{H}(z\mid s)\]- DIAYN에서 유래한 접근으로 RGSD의 기반이 되는 방법
- $\mathcal{H}(\cdot)$ shannon entropy
- 확률변수의 불확실성, 무질서도를 수량화한 척도.
- 어떤 사건이나 변수가 얼마나 ‘예측하기 어려운지’를 측정
- 엔트로피가 높으면 : 정보가 ‘surprise’가 크고, 예측이 어려움
- $H(x) = -\sum_i p(x_i)\log_2p(x_i)$
- $\mathcal{H}(\cdot)$ shannon entropy
- $\mathcal{I}(s;z)$를 최대화해서 다양한 스킬 $z$ 가 서로 다른 상태 $s$ 를 유발하도록 한다
- $\mathcal{I}(s;z)$가 커지면 스킬 $z$과 상태 $s$가 강하게 연결되어 예측 가능한(=의미있는) 스킬을 발견하는데 이는 고차원 시스템에서 무의미한 동작을 피하는데 중요함
- DIAYN에서 유래한 접근으로 RGSD의 기반이 되는 방법
- $\mathcal{H}(z\mid s)$ 가 interactable(계산 불가능)하기 때문에, DIAYN에서는 뉴럴넷 인코더 $q_\phi(z\mid s)$를 도입해 variational lower bound $\mathcal{G}(\theta, \phi)$를 skill discovery objective $\mathcal{F}(\theta)$ 의 근사로 사용
-
USD Objective Function
\[\mathcal{F}(\theta) = \mathcal{I}(s;z) + \mathcal{H}(a|s,z) \\ \ge \mathbb{E}_{z\sim p(z), s\sim \pi(z)} [-\log p(z) + \log q_\phi(z|s) + \mathcal{H}[\pi_\theta(\cdot|s,z)]] \triangleq \mathcal{G}(\theta, \phi)\]- Optimization Process
- 정책 최적화 $\pi_\theta$ : maximize via RL with reward $r_z = -\log p(z) + \log q_\phi(z\mid s)$
- 인코더 최적화 $q_\phi$ : maximize $\log q_\phi(z\mid s), \quad s\sim \pi(\cdot\mid s,z)$
- Optimization Process
Reference Grounded Skill Discovery (RGSD)
- 기존 USD 방법들과는 다른 순서로 접근
- 기존 USD 방법들은 먼저 정책의 탐색으로 시작. 에이전트가 환경에서 무작위로 행동하면서 데이터를 먼저 수집하고 그 후에 데이터를 바탕으로 잠재 공간을 유도해서 다른 영역이 다른 행동을 나타내도록 강제하는 방식으로 ⇒ 탐색이 선행되고 나서 잠재 공간이 사후적으로 구조화되는 방법
- RGSD는 목표행동(target behavior)의 데이터셋에서 부터 시작. 환경과의 상호작용 없이 먼저 데이터셋을 unit hyperspherical 잠재공간에 임베딩. 이상적인 잠재공간은 각 모션이 하나의 방향 벡터 $z$로 표현되고, 다른 모션 간에 명확한 분리가 이루어진 형태인데. 이 구조가 탐색을 상태 공간에서 구조화된 스킬 발견으로 변환시킨다는 점이 핵심 아이디어. (이때 contrastive learning이 사용됨)
- unit hypersphere
- 고차원 공간에서 반지름이 1인 구의 표현.
- unit sphere : 3차원에서 반지름이 1인 구의 표면
- hypersphere : k-차원 공간에서 반지름이 1인 초구의 표면
- $Z = {v\in\mathbb{R}^k : \lVert v \rVert_2=1 }$
- unit hypersphere의 핵심은 “방향”을 강조한다는 점.
- 모든 벡터의 길이가 1이므로, 두 벡터 간의 유사상은 코사인 유사도로 측정되고, 각도에 따라 -1 ~ 1 까지 변함.
- unit hypersphere
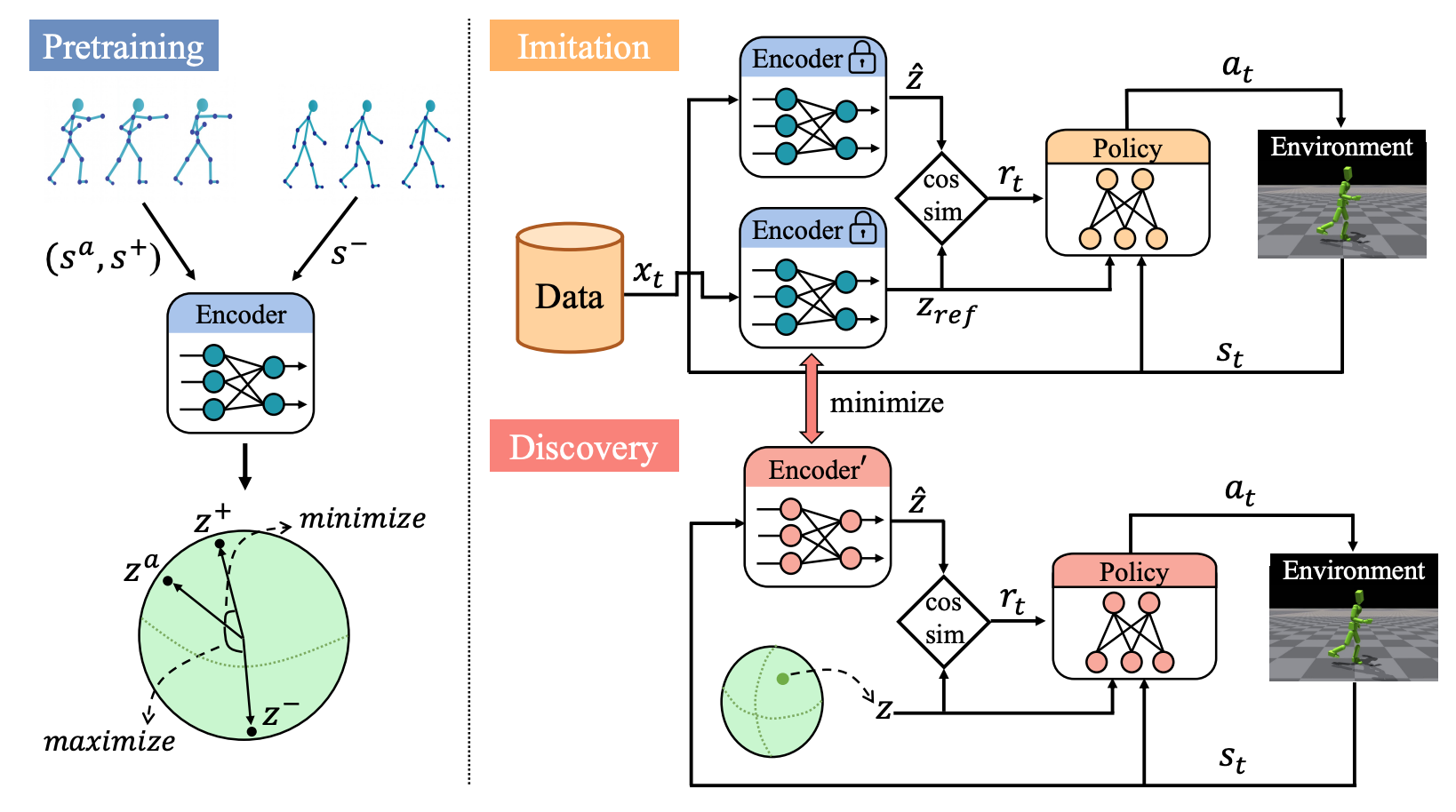
1. Pretraining: Grounded Latent Space on Reference Motions
- 환경과의 상호작용 없이 참조 모션을 사용해 잠재공간을 semantically meaningful하게 그라운딩하는 단계로. RGSD는 이 단계를 통해 고차원 시스템의 무의미한 탐색을 방지한다
- 사전훈련의 목적은
- 각 모션 trajectory를 잠재벡터 $z$에 연관 짓는 것으로 skill-conditioned policy $\pi(\cdot\mid s,z)$가 해당 trajectory를 재현할 수 있도록 하는데에 있다
- 이를 위해 각 모션을 hypersphere 상의 한 점으로 배치하면서 다른 모션 간의 분리를 보장한다
- 같은 trajectory에서 샘플링된 상태 쌍은 positive pairs로 유사하게 클러스터링 되고, 다른 trajectory에서 샘플링된 쌍은 negative paris로 멀리 배치된다
- 각 모션이 고유한 잠재방향 주위에 강하게 클러스터링되어 downstream imitation과 discovery를 위해 잘 구조화된 공간을 먼저 형성한다.
- 무작위로 잠재공간을 채우는게 아닌 잠재공간이 참조 데이터의 의미를 반영하도록 먼저 grounding 하는 게 RGSD의 핵심 아이디어!
- 인코더 $q_\phi(z\mid s)$ 로 훈련하는데 인코더는 상태를 잠재벡터 $z$에 대한 확률 분포로 매핑한다
- 인코더는 von mises-Fisher (vMF) 분포로 모델링
- vMF는 hypersphere에서 방향성을 다루는 분포로, $\mu_\phi(s)$ 가 $z$-방향으로 끌어당기는 힘을 $\kappa$만큼 강하게 적용하는데. 이는 모션의 상태들이 하나의 방향으로 정렬되로록 유도한다
- Pretraining Process:
- sample motion $m \sim \text{Uniform}(\mathcal{M})$
- select a pair of states $(s^a, s^+)$
- negative sample $s^-$ drawn from $\mathcal{M} \backslash {m}$
- embed as $z^a = \mu_\phi(s^a), \quad z^+=\mu_\phi(s^+), \quad s^-_j=\mu(s^-_j)$
- optimize the InfoNCE Loss \(\mathcal{L}_\text{InfoNCE} = -\log \frac{\exp(\text{sim}(z^a,z^+)/T)}{\exp(\text{sim}(z^a,z^+)/T) + \sum_j\exp(\text{sim}(z^a,z^-_j)/T)}\)
- 같은 모션의 상태들이 동일한 $z$로 취급되도록 훈련하여 결과적으로 잠재 공간을 참조 데이터의 의미를 반영한 구조화된 매니폴드로 만들어 의미있는 탐색이 가능하도록 한다

정리하면, pre-training은 모션 시퀀스들로 구성된 참조 데이터셋을 활용해 인코더를 훈련시켜 unit hypersphere 상의 잠재 공간을 grounding하는 과정으로. 같은 trajectory 내의 상태들은 hypersphere 상에서 아주 가까이에 위치하도록 하고, 다른 trajectory의 상태들은 저 멀리 떨어뜨리도록 한다. 그 결과 잠재공간이 먼저 의미적으로 구조화 되어, 추후 에이전트가 고차원 공간에서 무의미한 탐색을 하지 않을 수 있게 돕는다.
2. Imitation of Reference Skills
- 사전 훈련된 인코더 $q_\phi$를 고정하고, 각 참조 모션의 상태들로부터 평균을 내어 만든 중심 방향 $z_m$을 잠재공간에 정의한 후, 이 $z_m$을 스킬로 정책에 주입하면 에이전트가 그 모션을 재현하도록 유도한다
- 여기서 사용하는 보상은 단순한 모방이 아닌, 모션의 상태와 에이전트의 현재 상태 사이의 코사인 유사도 즉 잠재 공간에서의 방향 일치를 기반으로 하는데, 모션의 정확한 상태를 방문했을 때 최대값을 얻고, 벗어날 수록 점점 작아지는 특성을 지닌다. \(r(s,z_m) = -\log p(z)+\log q_\phi(z_m\mid s) \\ = C + \kappa \mu_\phi(s)^\top z_m\)
- 실제 학습에서는 에이전트가 참조 모션에서 시작하고 너무 벗어나면 조기종료하여 신뢰할 수 있고 안정적인 모방학습을 가능하게 한다
- DeepMimic이나 MaskedMimic에서는 Joint-level 유사도로 보상을 측정하는 반면, RGSD에서는 학습된 잠재 공간에서 유사도를 평가하는데. 고차원 시스템에서 더 추상적이고 의미있는 모방을 가능하게 한다는 점에서 의의가 있음
3. Discovery of New Skills
- 참조 데이터를 기반으로 잠재공간에서 새로운 행동을 발견하는 방법에 대해서 다루는데, Discovery는 DIAYN을 따르지만, 고차원 자유도 시스템의 한계를 극복하기 위해 3가지 차이점을 도입하여, Imitation과 Discovery를 안정적으로 통합하고, Disjoint Skill set 문제를 방지한다
- Discovery 과정은 RGSD의 grounding된 잠재공간을 활용해 기존 행동과 semantic하게 관련된 새로운 스킬을 발견하도록 설계되었다
- DIAYN은 MI를 최대화해서 무작위 잠재벡터 $z$를 샘플링해서 다양한 행동을 유도하지만, 고차원에서 무의미한 행동이 발생하기 쉽다. 이를 보완하기 위해 RGSD는 다음과 같은 3가지 주요 차이점을 도입한다
- 학습된 잠재 공간 보호를 위해 별도의 인코더 $q’_\phi$ 초기화와 KL-divergence 최소화
- 새로운 스킬이 참조 데이터셋의 의미있는 매니폴드 내에서만 탐색된다
- Imitation과의 병렬 훈련으로 Knowledge Transfer
- 공유된 Policy와 value function이 imitation에서 배운 high fidelity behavior를 discovery로 전이하도록 한다
- 보상함수와 잠재 공간 공유하므로 공유 컴포넌트가 안정적으로 최적화 될 수 있다
- Reference State Initialization (RSI) 도입
- 초기 상태를 참조 모션에서 직접 샘플링하는 RSI 사용
- imitation과 discovery가 overlapping state distribution에서 작동하도록 보장해서 disjoint skill sets의 등장을 방지함. → 무의미한 행동을 피할 수 있음
- 학습된 잠재 공간 보호를 위해 별도의 인코더 $q’_\phi$ 초기화와 KL-divergence 최소화
- 잠재공간의 단위 지오메트리를 활용해 참조 방향 사이에서 z를 샘플링해서 새로운 스킬을 유도한다

Experimental Results and Discussion
- 4 Questions:
- Can RGSD imitate reference motions with high fidelity?
- Can RGSD discover novel skills that are still semantically related to the references?
- Can the learned skills be effectively leveraged for downstream tasks?
- Can RGSD be integrated with METRA?
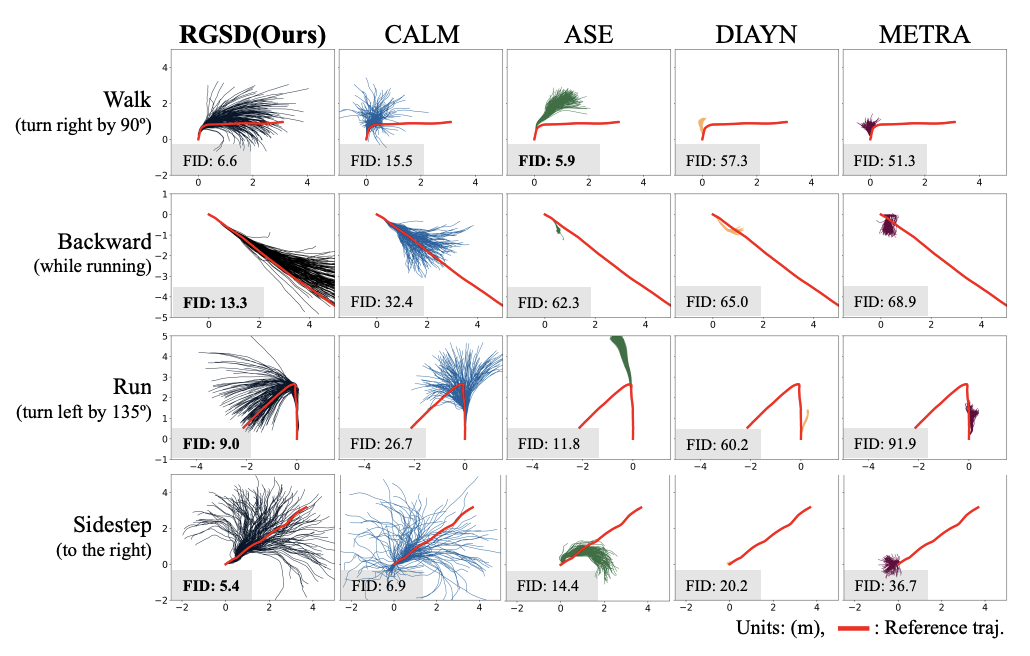
Evaluation of Imitation
- how well RGSD reproduces reference motions
- generate 500 trajectory