![[논문 리뷰] Policy Agnostic RL: Offline RL and Online RL Fine-Tuning of Any Class and Backbone](/assets/img/250327/image_5.png)
[논문 리뷰] Policy Agnostic RL: Offline RL and Online RL Fine-Tuning of Any Class and Backbone
작성자: 민예린
논문 정보
제목: Policy Agnostic RL: Offline RL and Online RL Fine-Tuning of Any Class and Backbone
저자: Max Sobol Mark, Tian Gao, Georgia Gabriela Sampaio, Mohan Kumar Srirama, Archit Sharma, Chelsea Finn, Aviral Kumar.
학회: Preprint
1. Intro.
연구 배경
- 최근 Imitation learning이나 offline RL에서 거대 모델 / 데이터를 기반한 연구의 성능들이 많이 올라가고 있다.
- 그러나 실제로 사용하기 위해서는 1번의 학습으로는 성능이 충분하지 않은 경우가 많고 fine tuning 이 필요하다.
- 예를 들어, picking 로봇에서 picking 물체가 바뀌는 경우 이에 맞는 adaptation을 해줘야 한다.
- 일반적으로 Pre-train 때 사용한 policy class를 활용해 fine tuning 을 하는데, 만약 policy class를 변경하면 학습이 매우 불안정해지는 경향이 있다.
- 예를 들어, SAC (Soft Actor-Critic) 알고리즘은 reparameterization 기법을 사용하기 때문에 Gaussian (or tanh-Gaussian) polices 에서는 안정적으로 학습되지만 diffusion policy로 바꾸면 학습이 불안정해진다.
- 비슷하게 CQL(Conservative Q-Learning)은 autoregressive token-based action distributions에 적용할 때 불안정해져서 loss function을 수정해줘야 한다.
- 즉, fine tuning 시에 다른 policy class에 확장하는 건 어려운 문제이기 때문에 보통 최적이 아닌 알고리즘을 선택하거나 추가적인 수정을 해야 하는 상황에 놓이게 된다.
PA-RL (Policy-Agnostic RL)
- PA-RL은 추가적인 수정없이 어떤 back bone 에도 효과적으로 사용할 수 있는 방법론이다.
- 기존 방법 : Policy parameters를 직접 최적화한다.
- PA-RL : actions 자체를 최적화하기 때문에 policy improvement를 parametric policy 학습과 분리할 수 있다.
- 이렇게 하면, 정책 학습을 optimized actions의 likelihood를 최대화하는 supervised learning 문제로 변환할 수 있다.
💡PA-RL 과정
- base policy에서 여러 개의 actions를 샘플링
- Q-function을 이용해 행동 최적화
- Global optimization : Q-function을 이용해 action samples를 re-ranking
- Local optimization : 샘플링된 action에 대해 gradient steps 수행
- Optimized actions을 기존에 샘플링한 actions 대신 사용해 policy update
2. Related work
현재 알고리즘들의 문제
- 최근 연구들을 보면 policy learning 이 Offline RL에서 병목이 될 수 있음을 보여주었다.
- 기존의 RL 알고리즘들은 특정한 policy class에 맞춰서 설계하는 경향이 있다. (대부분 Gaussian policy를 중심으로 한다.)
- 하지만 이렇게 특정한 유형에만 최적화된 알고리즘들은 overfitting 문제나, 다른 policy 유형에서의 성능 이슈가 존재한다.
- Wang et al.[1] 에서는 sub-optimal data에서 성능이 떨어진다.
- DDPM loss를 기반으로 offline checkpoint 를 선택하는 방식을 취한다고 한다.
- Hansen-Estruch et al. [2]은 TD3+BC처럼 완전한 policy gradient 방식을 사용하는 방법보다 성능이 떨어진다.
- Q-function 기반의 re-ranking 기법을 사용한다.
- 또한 autoregressive policy를 Offline RL로 fine-tuning 하기 위해서는 value function을 수정해야 하는 이슈가 있다.
- 대부분의 offline RL 알고리즘들은 autoregressive categorical transformer policies를 학습할 때 지도학습 방식을 사용하고 있다. (ex. BC 변형, Decision Transformer)
- 이런 방식은 최적의 policy를 학습하기에는 한계가 존재한다.
Diffusion 정책을 fine-tuning 하는 연구들
- DPPO : two-layer diffusion-specific policy gradient loss를 사용한다.
- PA-RL은 diffusion 외에도 다른 policy class에 적용 가능하다.
- IDQL : IDQL은 Q-러닝의 변형이다.
- PA-RL의 global optimization 단계처럼 행동 재정렬(re-ranking)을 통해 정책을 개선한다.
- 그러나 re-ranking actions를 반복적으로 distill 하지 않기 때문에 fine-tuning 성능이 떨어진다.
- PA-RL은 IDQL 보다 성능이 좋고 autoregressive categorical transformer policy를 offline RL 및 online fine-tuning 할 수 있다.
- DIPO, DDiff PG : PA-RL의 local optimization 단계처럼 action gradient를 사용하지만, online RL 세팅에만 동작하며 pre-training을 포함하지 않는다.
- DQL : reparametrized policy gradient estimator 를 사용하지만, 불안정하며 특정한 checkpoint 선택 및 regularization이 필요하다.
- 그 외에도 score matching을 통한 diffusion 정책 방식도 있지만 이 또한 매우 불안정하다.
PA-RL의 차별점
-
방법론적으로 볼 때, PA-RL은 “RL을 지도학습 문제로 변환”하는 기존의 접근법들과 유사해 보일 수 있다. 하지만 기존들과 다음과 같은 중요한 차이점을 가진다.
💡- 기존 연구들은 데이터셋 / 리플레이 버퍼에 저장된 행동을 Negative log likelihood로 학습한다.
- 반면, PA-RL은 정책에서 새로운 actions을 샘플링하고, Q-function을 이용해 최적화한 후 이 행동을 NLL로 학습한다.
-
이러한 차이로 인해 aggressive updates를 할 수 있고 supervised regression의 slowness 문제를 피할 수 있다.
- Tajwar et al.[5]를 보면 weighted regression loss로 policy가 수집한 행동에 가중치를 주어 학습하면, 일반적인 policy gradients와 유사하게 특정 행동을 선호하는 경향을 볼 수 있다.
- 즉 기존 강화학습의 특징처럼, 학습할 수록 선호하는 action을 찾아가는 방식으로 동작하게 되는 것 같다.
- 기존의 데이터셋에서 샘플링한 actions만 사용하는 방식은 이런 특성을 나타내지는 못한다.
기존 CEM 기반 방법과 PA-RL의 비교
- PA-RL은 Online RL 세팅에서 Q-function 기반의 CEM(Cross-Entropy Method)와 유사한 측면이 있고, 지도 학습 기반의 정책 개선 방식과도 관련이 있다.
- 하지만 Offline RL 사전 학습으로 proposal distribution을 학습하는 과정이 추가된다.
- 이를 통해 Q-function이 OOD 에서 잘못된 값을 생성하는 문제를 완화할 수 있다.
- Proposal distribution : 무엇을 샘플링할지 정의하는 확률 분포
3. Problem Setup and Preliminaries
Problem setting
- Fully offline RL
- 주어진 데이터셋을 이용해 정책을 학습하는 방식
- behavior policy로 수집된 데이터셋을 사용
- Offline to Online finetuning
- offline 데이터로 초기 정책 학습 ( $𝜋_{off}$ )
- Online 환경에서 추가 학습 진행 (최소한의 online samples를 이용해 최적 정책을 빠르게 찾는 것)
Policy classes and parameterizations
두 가지 유형의 정책을 fine tuning 하는 실험을 진행했다.
- Diffusion Policies : 연속적인 행동을 생성하는 정책이다.
- State s에 대해 diffusion model (DDPM; Denoising Diffusion Probability Model)을 활용하여 action distribution을 모델링
-
DDPM은 denoising model을 아래와 같은 loss function으로 학습한다.
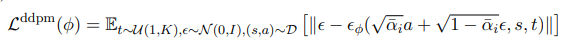
- forward diffusion 프로세스에서 초기 샘플을 𝑎𝐾 ∼ 𝒩 (0, 𝐼) 기반으로 노이즈를 주다가 점진적으로 디노이징하여 최종 행동 a를 생성한다.
- Autoregressive Policies : Transformer 아키텍처를 기반으로 하고, 범주형 action tokens을 생성하는 방식이다.
-
Autoregressive Policies는 아래와 같이 표현된다.
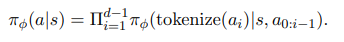
- 각 action dimension 마다 conditional categorical distribution을 정의하고 이를 곱해서 전체 행동의 확률 분표를 표현하는 방식이다.
- 이 실험에서는 각 행동 차원을 128개의 bin으로 분할했고, OpenVLA tokenizer를 사용하여 action을 토큰화했다.
-
Offline RL and online fine-tuning methods
- PA-RL은 policy optimization 과정이 차이가 있고, critic 은 base algorithm을 유지했다.
-
기본적으로 actor-critic 기반의 알고리즘을 사용하는데 이때
(1) IQL처럼 actor 와 critic 을 분리해서 업데이트 하거나
(2) Cal-QL처럼 Critic 학습 시 actor의 sample을 사용하는 방식 두 가지에 집중했다.
CAL-QL의 critic training 목적 함수

-
첫 번째 텀 디테일
경우 max(Q, V^μ) - Q 손실 기여도 학습 방향 Q > V^μ (과신) Q - Q = 0 (하지만 위 Q는 OOD) ↑ Q를 억제 Q < V^μ (비관) V^μ - Q > 0 ↑ Q를 끌어올림 Q ≈ V^μ 손실 적음 → 그대로 유지 -
두 번째 텀 설명
- 정책 기반으로 future Q를 학습하고 탐색 가능성 확보
- 현재의 Q 값이 미래의 Q을 따라가도록 하는 TD loss
IQL
- 반면, IQL은 정책에서 새로운 행동을 샘플링하지 않는 방식으로 학습한다.
- 컨셉은, 신뢰할 수 있는 Q만 사용하여 V를 보수적으로 업데이트 하는 것이다.
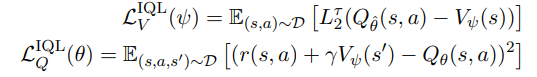
-
4. Policy Agnostic RL (PA-RL)
사용 대상
- Autoregressive token-based policies
- Diffusion / Transformer 백본
Off2On에 Policy Agnostic 이 가능할까?
- 본 논문의 방법은 위 아이디어에 기반하고 있다.
- Policy가 생성한 행동들을 직접 최적화하고
- 최적화된 행동을 모방하도록 정책을 학습시킨다.
- 이와 같이 학습하면 (1) policy training 과 policy improvement 를 분리할 수 있게 되고 범용성을 가질 수 있게 된다.
Stage 1 : Action Optimization
목표
Q 값을 높이는 행동을 찾으면서, 이 행동이 기존의 데이터 분포로부터 너무 멀어지지 않도록 제한하는 것이다.
- Global optimization : pre-trained policy로부터 여러 action samples을 뽑고 Q값을 기준으로 상위 몇 개만 남긴다.
- Local optimization : 선택된 actions을 기준으로 Q function의 gradient를 따라 행동을 직접적으로 개선한다.
- $a←a+α∇aQ(s,a)$
- a을 바꿨을 때 Q 값이 변하는 방향만큼 a에 더해서 action을 조금씩 업데이트 한다.
- 이때 정책은 고정된 상태로 사용한다.
Stage 2 : Policy Training via Supervised Learning
목표
Optimized actions을 기반으로 supervised learning 기반의 정책 모방 모델을 만드는 것이다.
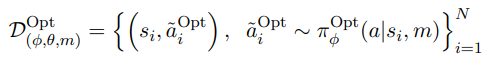
이때 distillation을 위해서 다음 두 가지 방식을 사용한다. ( 두 방식 중 적절한 것을 선택 )
- Q값이 가장 큰 행동을 선택하여 학습
- Stage 1에서 수집한 데이터를 이용하여 지도학습 진행
- Q값을 기반으로 여러 행동을 가중합한 분포로 정책을 학습
-
Softmax를 통해 각 행동에 대한 확률 분포를 만들고 해당 분포를 따라 행동을 샘플링한다.
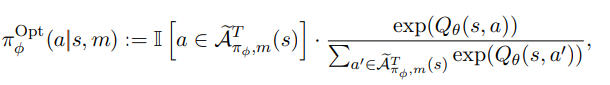
-
위처럼 샘플링을 하게 되면, top-1 action만 사용하지 않기 때문에 Critic이 부정확한 경우에 대한 영향력을 줄일 수 있고 actions 데이터를 추가적으로 사용할 수 있게 된다.
-
이후에는 위에서 수집한 데이터를 기반으로 diffusion이나 autoregressive policy 구조에 맞춰서 BC loss를 사용하여 학습하면 된다.

5. Experimental Evaluation
실험 목표
다양한 형태의 정책을 얼마나 효과적으로 fine-tuning 할 수 있는지 확인
Results: Simulated Benchmarks from State and Image Observations
PA-RL은 Cal-QL 또는 IQL을 기반으로 실험을 진행한다.
비교할 기존 diffusion 방법론들
- IDQL : IQL을 확장해 diffusion policy를 critic 기반 re-ranking으로 학습
- DPPO : imitation learning으로 학습된 diffusion policy를 PPO로 파인튜닝
- DQL : SAC 방식과 유사하게 reparametrized policy gradient로 diffusion policy 학습
실험 환경 (Domains and Tasks)

- AntMaze (D4RL): 관절 로봇으로 미로 통과, sparse reward 환경
- FrankaKitchen: 9-Dof Franka robot, 주방 환경에서 주방 환경에서 4 manipulation tasks 수행
- CALVIN [32, 46]: 테이블 환경에서 선택지가 있는(distractor objects) 4 manipulation tasks 수행. 가장 어려운 과제.
-
특히 어려운 이유: 시각 입력(이미지)만으로 정책을 학습해야 하고, 오프라인 데이터는 사람의 원격 조작으로 수집되어 액션 커버리지는 낮지만 의미론적 다양성(behavioral mode)은 높음
→ 즉 diffusion policy의 muti-model 표현력을 테스트하기 적합한 환경
-
-
✅ 결과 : Diffusion Policy 기반의 학습에서 PA-RL 성능 (Cal-QL)
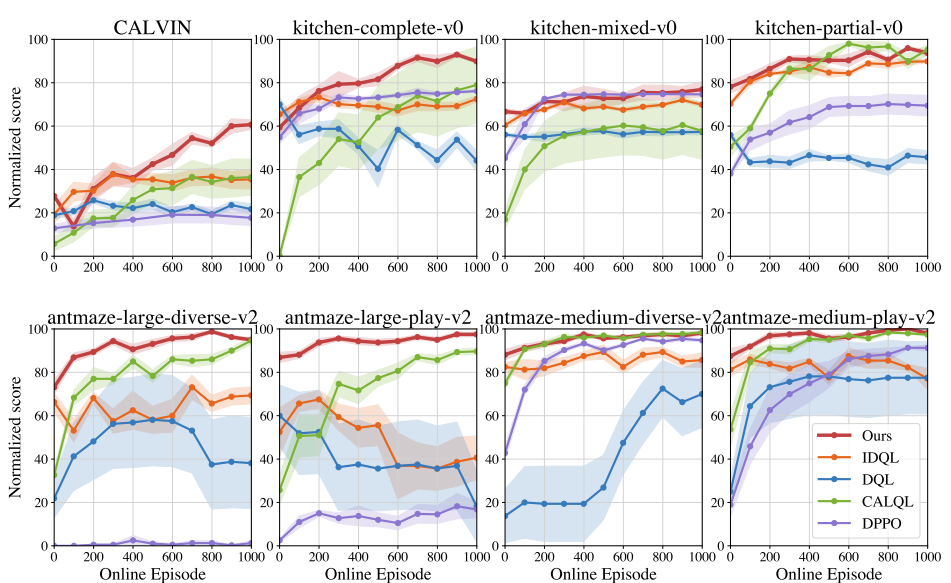
- 평균적으로 13% 더 높은 fine-tuning 성능
- CALVIN에서는 69%나 향상, 특히 시각 입력 기반 조작에서 강력함
-
✅ 결과: Hybrid RL 환경에서의 PA-RL 성능 (RL with Prior Data)

- Pretraining 없이 offline data를 online 학습에 사용
- 기존에는 tanh-Gaussian policy 사용, 여기선 diffusion policy로 대체하고 critic은 random 초기화
- 결과
-
diffusion policy의 imitation 성능을 시작점으로 하여, 200 에피소드 내에 Gaussian보다 훨씬 우수한 성능 도달
→ PA-RL이 policy 표현력을 얼마나 잘 활용하는지 보여줌
-
- ✅ 결과: Autoregressive Categorical 정책에 PA-RL + Cal-QL
- 위 Table 오른쪽
-
PA-RL + Cal-QL은 이 구조에서도 평균 26% 성능 향상 (tanh-Gaussian 대비)
→ 다양한 정책 클래스에서도 PA-RL은 강력한 fine-tuning 성능을 보여줌
-
- 위 Table 오른쪽
Results: RL Fine-Tuning of Robot Policies in the Real World
Real-world robot and task setup

- 로봇 팔, 카메라 부착되어 있음
- 세 가지 tasks
- Cup to drying rack : 컵을 잡고 싱크대 너머 건조대에 올려두기
- Pot to sink : 건조대에서 냄비를 잡아 싱크대로 이동
- Vegetable to sink : 양배추를 들어 싱크대 안 접시에 올림
Fine-tuning Real-World Diffusion Policies

- PA-RL을 통해 태스크 (1), (2) 모두에서 성공률이 75~100% 향상 됐다.
- 40~110분 내의 학습만으로 매우 효율적인 성능 개선을 할 수 있었다.
- “컵을 건조대에 놓기” 태스크에선 초반 50 에피소드 동안 성능 하락이 있었지만,
- 이후 20 에피소드 내에 빠르게 회복 및 향상되었고, 이는 expressive한 정책 구조 덕분에 빠른 적응이 가능했다고 판단된다.
OpenVLA Fine-Tuning in the Real World
- 7B OpenVLA를 실제 로봇에 fine tuning 진행했고 Large policy를 자동적으로 fine tuning 하게 하기 위해 여러 설계를 적용했다.
- 학습 단계
- Offline RL 단계 : Critic만 학습
- OpenVLA로 행동을 샘플링하여 캐시로 저장
- Online fine tuning 단계 : OpenVLA의 정책 파라미터를 업데이트
- Offline RL 단계 : Critic만 학습
-
결과

- OpenVLA 초기 성능 (zero-shot): 성공률 40%
- PA-RL로 40분 동안 파인튜닝 후 → 성공률 70% 도달
- fine-tuning 후 distractor 객체와 관련된 오류가 현저히 줄어듦
- 예: 잘못된 물체를 집거나, 집었다가 놓치는 현상 줄어듦
- 개선된 정책은 목표 물체를 더 정확하게 파악하고 안정적으로 집음
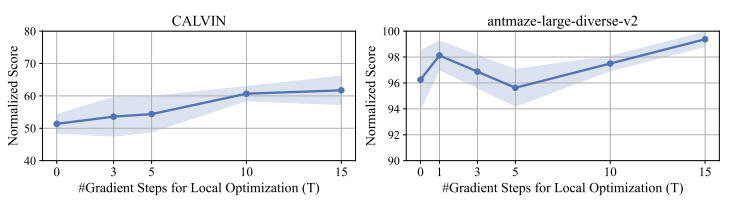
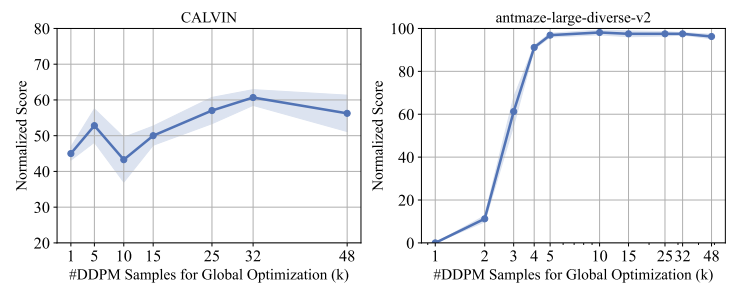
Global 및 Local Optimization의 영향
- 두 가지 태스크(antmaze-large-diverse, CALVIN)에서 실험을 수행
-
Antmaze-large-diverse에서는 글로벌 최적화가 매우 중요, 로컬 최적화는 영향이 크지 않다.
-
CALVIN에서는 글로벌 + 로컬 둘 다 중요함
-
시사점
- 글로벌 최적화는 거의 항상 중요하고, 로컬 최적화는 데이터셋의 다양성이 낮을 경우 특히 효과적이다.
6. Discussion and Conclusion
- 정책에서 여러 행동을 샘플링하여 사용하는 부분이 계산 비용이 매우 크기 때문에 이런 부분을 줄이기 위한 이이디어가 필요하다.
- global와 local optimization의 상호 작용을 더 잘 이해해야 한다.
- generalist critic model을 학습하는데 적합한 방법을 개발해야 한다.
Reference
[1] Zhendong Wang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning.
[2] Philippe Hansen-Estruch, Ilya Kostrikov, Michael Janner, Jakub Grudzien Kuba, and Sergey Levine. Idql: Implicit q-learning as an actor-critic method with diffusion policies. arXiv preprint arXiv:2304.10573, 2023.
[3] Seohong Park, Kevin Frans, Sergey Levine, and Aviral Kumar. Is value learning really the main bottleneck in offline rl? arXiv preprint arXiv:2406.09329, 2024.
[4] Yevgen Chebotar, Quan Vuong, Karol Hausman, Fei Xia, Yao Lu, Alex Irpan, Aviral Kumar, Tianhe Yu, Alexander Herzog, Karl Pertsch, et al. Q-transformer: Scalable offline reinforcement learning via autoregressive q-functions. In Conference on Robot Learning, pages 3909–3928. PMLR, 2023.
[5] Fahim Tajwar, Anikait Singh, Archit Sharma, Rafael Rafailov, Jeff Schneider, Tengyang Xie, Stefano Ermon, Chelsea Finn, and Aviral Kumar. Preference fine-tuning of llms should leverage suboptimal, on-policy data. In Forty-first International Conference on Machine Learning.