![[논문 리뷰] Flow Q-Learning](/assets/img/250227/image_8.png)
[논문 리뷰] Flow Q-Learning
작성자: 이동진
논문 정보
제목: Flow Q-Learning
저자: Seohong Park, Qiyang Li, Sergey Levine, UC Berkeley.
학회: ICML 2025
Overview
- Target task: Offline RL
-
Algorithm class: TD3 + BC 등 behavior regularization actor-critic 기법
\[\begin{matrix} \mathcal{L}_\pi (\theta)& = &-\mathbb{E}_{(s,a)\sim \mathcal{D}, a^{\pi} \sim \pi_\theta (\cdot \mid s)} \left[ Q_{\phi}(s, a^{\pi}) + \alpha \log \pi_\theta(a \mid s ) \right], \\ & = & \text{Q loss} + \text{BC loss}. \end{matrix}\] - Motivation: Denoising diffusion나 flow matching 등의 표현력이 좋은 iterative 생성 모델을 정책으로 사용하고 싶다.
- 그 중 flow matching이란 생성 모델 사용
- Challenge: Flow matching을 policy로 사용 시 backpropagation through time (BPTT)이 수반되며, 이로 인한 학습 불안정성 존재
- Solution
- 학습 중인 $\pi_\theta$는 우리가 잘 아는 Gaussian policy로 유지하되,
- Behavior policy $\pi_\beta$만 flow matching 생성 모델로 학습시키고, $\pi_\theta$가 $\pi_\beta$를 따라하도록 BC하자.
Preliminaries
Flow matching
Flow matching?
- 데이터 분포에서 샘플링이 가능한 generative model
- DDPM처럼 샘플링에 iterative한 과정이 있는 iterative generative model
Flow matching 이전
](/assets/img/250227/image.png)
Normalizing Flow: 초창기 flow-based models는 random vector를 여러 번 change of variables을 하여 간단한 random vector를 복잡한 random vector로 변환
- Change of variables 함수 $f_i$ 들이 invertible 해야 한다는 제약 조건 발생
](/assets/img/250227/image%201.png)
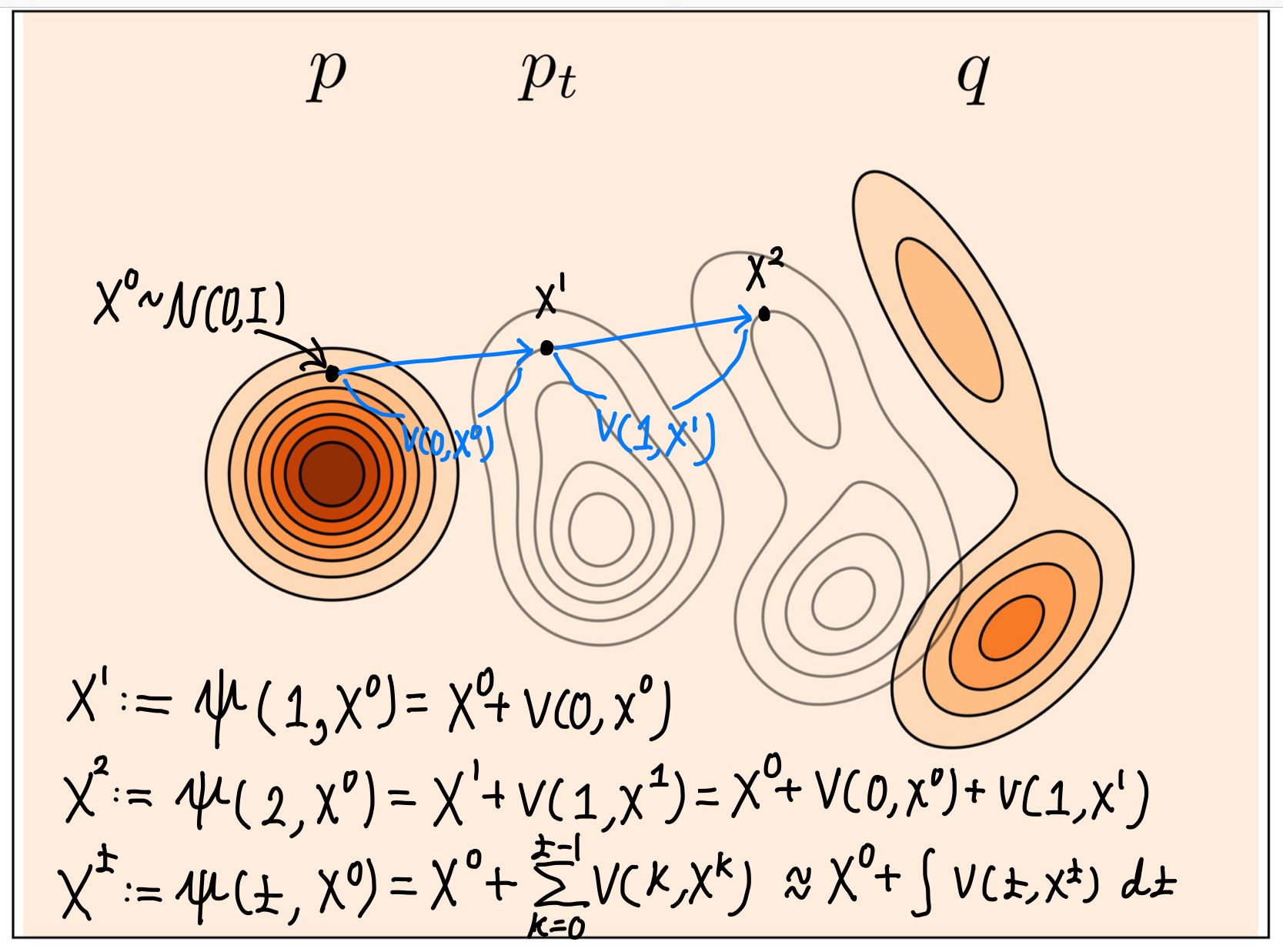
Continuous normalizing flow
다음과 같은 함수가 있다고 생각해보자.
- Time dependent function $\psi (t, x): [0,1] \times \mathbb{R}^{d} \rightarrow \mathbb{R}^{d}$ where for $0 \le t \le 1$.
- $t=0$ 일 때, $\psi (0, x) =x$.
- If a random vector $X^0 \sim \mathcal{N}(0, I_d)$, then the random vector $\psi (0, X^0) \sim \mathcal{N} (0, I_d)$.
- $t=1$ 일 때, a random vector $\psi (1, X^0) \sim p$ where $p$ is a target data distribution,
- governed by the following ordinary differential equation:
- where $v(t, x): [0, 1] \times \mathbb{R}^{d} \rightarrow \mathbb{R}^d$ is a velocity field.
- $t=0$ 일 때, $\psi (0, x) =x$.
위 식의 정체
1️⃣ $\psi(t, x)$는 change of variables 해주는 함수지 PDF는 아님. 한편, 어떤 random vector $X$를 함수 $\psi(t, x)$로 change of variables 해준 random vector $X^t = \psi(t, X)$가 갖는 확률분포를 $p_t$로 표기
2️⃣ $\psi(t, x)$을 explicit하게 구할 필요 없고, 식을 기술하기 위하여 implicit하게만 존재.
3️⃣ $\psi(t, x)$와 같은 함수를 flow라고 부름
4️⃣ 위 성질들을 만족시키는 $v(t, x)$를 찾고 싶은 것. 즉, 우리는 neural network $v_\theta(t, x)$으로 $v(t, x)$를 근사시킬 것이고 $v_\theta$로부터 implicitly 유도되는 함수를 $\psi_\theta(t, x)$으로 표기
-
이해를 돕기 위한 discrete 버전
$v_\theta(t, x)$ 학습 방법 (linear paths and uniform time sampling)
- $X^0 \sim \mathcal{N} (0, I_d)$ 과 $X^1 \sim p(X)$ 를 샘플링하였을 때,
- $X^0$ 에서 $X^1$ 으로 가는 방향 $X^1 - X^0$과
- $t$ 시점에서의 중간 변환물 $X^t = (1- t)X^0 + t X^1$ 에서의 velocity 방향을 맞춰줌
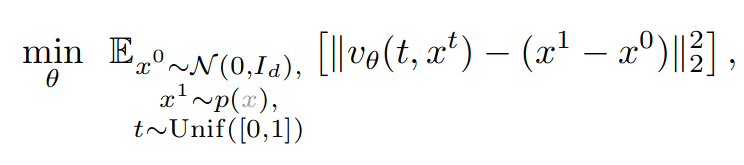
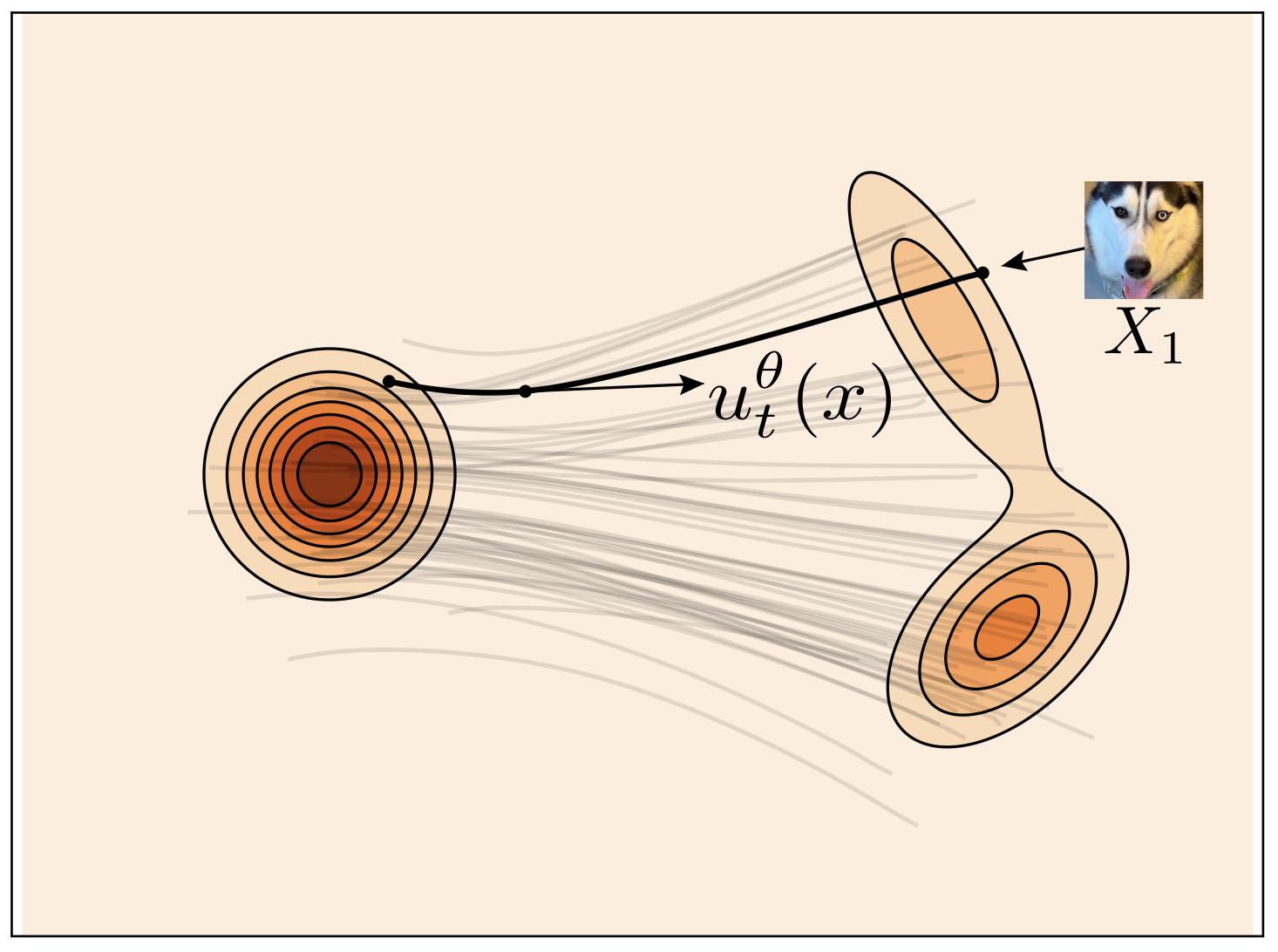
$v_\theta(t, x)$를 학습시킨 후 새로운 데이터를 $p(X)$에서 샘플링 하는 방법
- $X^0 \sim \mathcal{N}(0 , I_d)$
- $X^{t+1} = X^t + v_\theta(t/M, X^t)/M.$ (Euler method $\Delta t = \frac{1}{M}$, $M=10$)
Flow Policies
정책은 상태 $s$에 dependent한 확률분포이어야 하기 때문에 $v_\theta$에 상태 $s$를 입력으로 추가
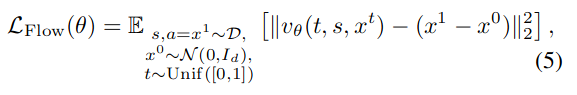
- Euler method를 통해 샘플링한 $\psi_\theta(1, s, z)$를 $\mu_\theta(s, z)$로 표기
- $\mu_\theta(s, z)$ 는 $s$와 $z$에 따라 값이 deterministic하게 결정되지만, $z$를 $\mathcal{N}(0 , I_d)$ 샘플링하며 바꿔줄 수 있기 때문에 stochastic policy 표기 $\pi_\theta (a \mid s)$를 사용
Flow Q-Learning (FQL)
Naive approach
- $\mathcal{L}_{\text{Flow}}(\theta)$는 학습한 $v_\theta$로부터 유도되는 정책 $\pi_\theta$가 데이터셋에 있는 행동 $a$를 생성해내도록 만들기 때문에 BC loss로 사용될 수 있음
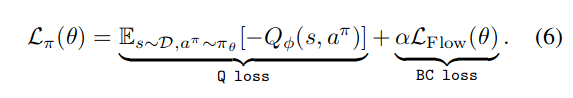
- 문제점: Q loss 계산을 위해 $a^{\pi}$를 샘플링할 때 $v_\theta$가 여러 번 호출되기 때문에 BPTT가 강제되고, 이로 인해 학습 불안정성 및 학습 시간 증가
Solution
- BC loss의 목적은 데이터셋 $\mathcal{D}$를 만들어낸 behavior policy와 현재 훈련 중인 정책을 비슷하게 만들어주는 것.
- $\mathcal{L}_{\text{Flow}}(\theta)$을 통해서는 behavior policy $\pi_\theta$만 만들고,
- Target policy $\pi_\omega$는 우리가 쉽게 사용하고 있는 아무 one-step samplig이 가능한 정책을 만들어서,
- $\pi_\omega$가 $\pi_\theta$를 따라하도록 BC loss를 디자인
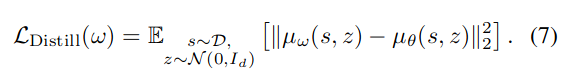
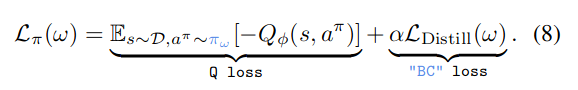
Experiment
Benchmarks
OGBench: Benchmarking Offline Goal-Conditioned RL

- 원래 OGBench는 goal-conditioned RL을 위한 벤치마킹
- (1) evaluation 할 때 episode마다 goal이 바뀜
- (2) dataset의 각 transition에 부여된 reward가 goal에 dependent
- 이 논문에서는 일반적인 offline RL을 평가하기 위해서 single task로 변경
- (1) 하나의 goal로 고정
- (2) dataset의 각 transition에 위에서 고정한 goal에 맞게 reward를 재부여
- 총 10개의 state-based 환경 (5개 locomotion, 5개 manipulation)
- 각 환경마다 5개의 goal을 고려하여 총 50개의 single task datasets 존재
- 총 5개의 visual-based task 데이터셋 존재
D4RL
- 6개의 AntMaze 데이터셋
- 12개의 Androit 데이터셋
Evaluation protocol
- OGBench에 대해서는 1M, D4RL은 500K 번의 gradient steps 후 evaluation 성능 비교
- State-based 환경은 8개, pixel-based 환경은 4개의 random seed에 대해서 반복 실험
Results
전체 성능표
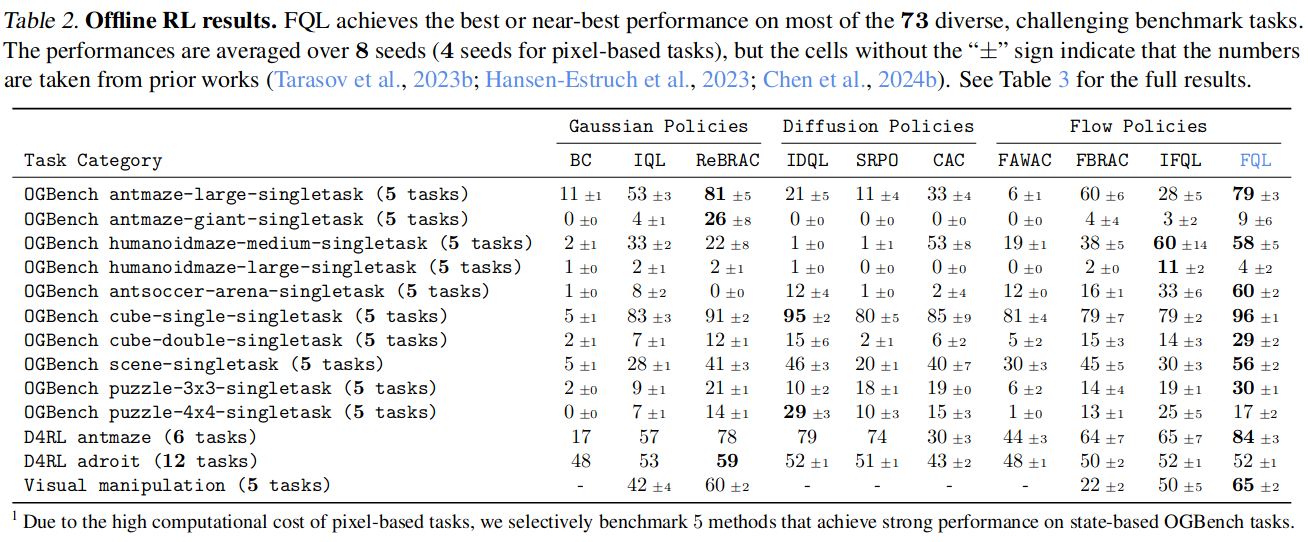
TD3 + BC 기법만 사용할 수 있는가?
- [Is Value Learning Really the Main Bottleneck in Offline RL?] 논문에서 고려하는 세 가지 policy extraction 기법 중 TD3 + BC 기법을 사용했는데, 다른 policy extraction 기법을 사용해도 되는가?

- AWAC: Q값을 weight로 줘서 log probability를 최대화하는 방법
- FBRAC: TD3 + BC인데 $\pi_\omega$ 없이 BPTT 그대로 하는 것
- IFQL: Behavior policy에서 직접 행동을 샘플링하여 그 중 학습한 Q값이 가장 높은 행동을 취하는 방법
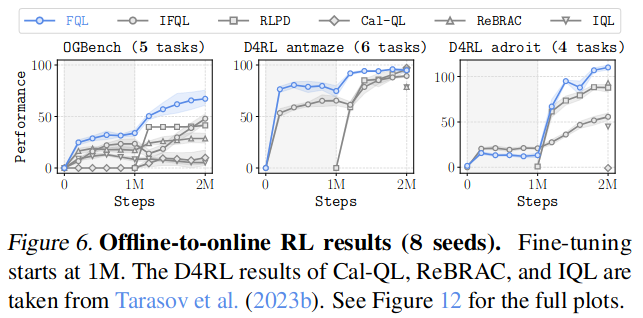
Offline-to-online finetuning
- 알고리즘 수정 없이 offline dataset이 담겨져 있는 buffer에 online transitions만 추가하여 fine-tuning 진행
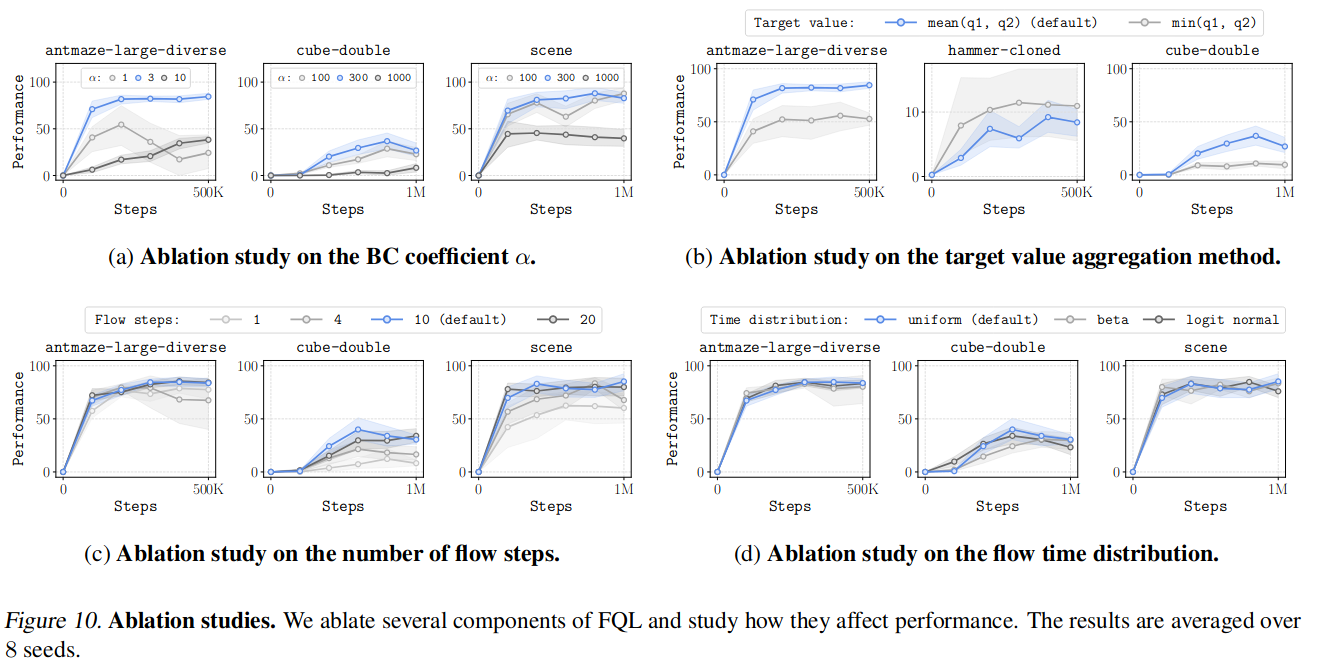
Hyperparameters
- BC loss에 대한 가중치 하이퍼파라미터 $\alpha$는 튜닝 필요, 나머지는 튜닝하지 않고 default 값 써도 좋음
- 데이터셋의 suboptimality에 따라서 적절한 $\alpha$ 값이 달라지기 때문
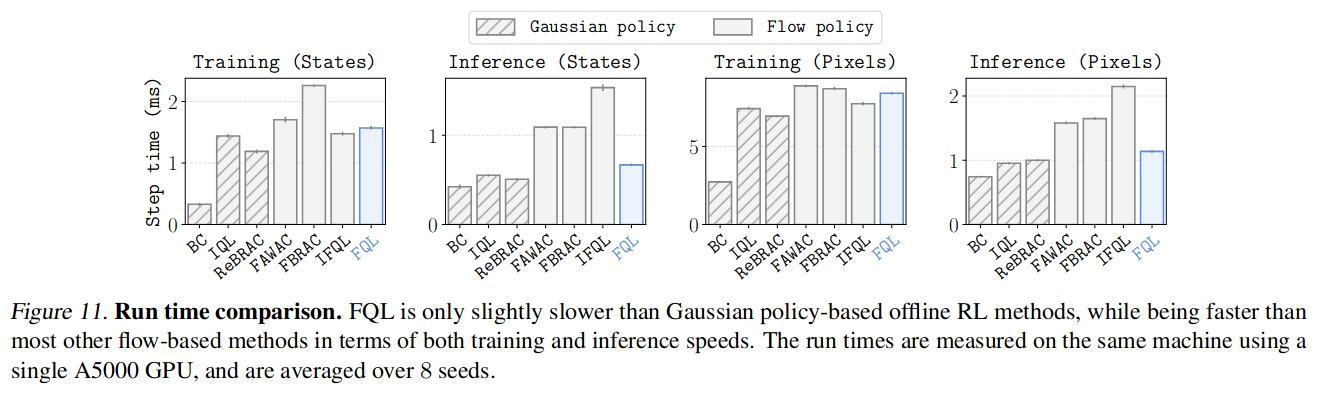
Time complexity