![[논문 리뷰] EXPO: Stable Reinforcement Learning with Expressive Policies](/assets/img/260402/image_1.png)
[논문 리뷰] EXPO: Stable Reinforcement Learning with Expressive Policies
작성자: 이동진
논문 정보
제목: EXPO: Stable Reinforcement Learning with Expressive Policies
저자: Perry Dong, Qiyang Li, Dorsa Sadigh, Chelsea Finn. Stanford & UC Berkeley.
학회: ICLR 2026
Overview
- Target task: Offline2Online fine-tuning for an expressive policy, Online RL
- Algorithm class
- Base policy: Diffusion policy, Behavior cloning
- Edit policy: Gaussian policy, Soft Actor-Critic
- Roll-out policy: Selecting from Behavior Candidates (SfBC)
- Motivation
- 사전 학습된 diffusion policy를 fine-tuning하는 연구가 거의 없다.
- Issue 1: Offline2Online fine-tuning에서 발생하는 distribution shift 문제
-
Issue 2: Diffusion policy를 online RL할 때 발생하는 unstable value maximization 문제
\[\max_{\theta} Q_\phi(s, a^{\pi_\theta}), \text{ where } a^{\pi_\theta}\sim \pi_\theta(\cdot \mid s).\]
- Solution
- Base policy: Fine-tuning 동안 diffusion policy는 behavior cloning을 통해 안정적으로 학습시키자.
-
Edit policy: Simple Gaussian edit policy $\pi_{\text{edit}}(\cdot \mid s, a)$를 사용해서 RL을 하자.
\[\max_{\theta_{\text{edit}}} Q_\phi(s, a+\hat{a}), \text{ where } a\sim \pi_{\theta_{\text{base}}}(\cdot \mid s) \, \text{ and } \, \hat{a}\sim \pi_{\theta_{\text{edit}}}(\cdot \mid s, a).\] - On-the-fly policy: Roll-out할 때와 TD target 계산할 때, sample-based action selection을 하자.
Introduction
- Imitation learning 분야에서 expressive policy를 이용해서 정책을 학습시키는 연구 활발
- 하지만 학습시킨 정책을 실제로 운용해보면 생각보다 잘 작동하지 않음
- Why? Distribution shift로 인한 error accumulation
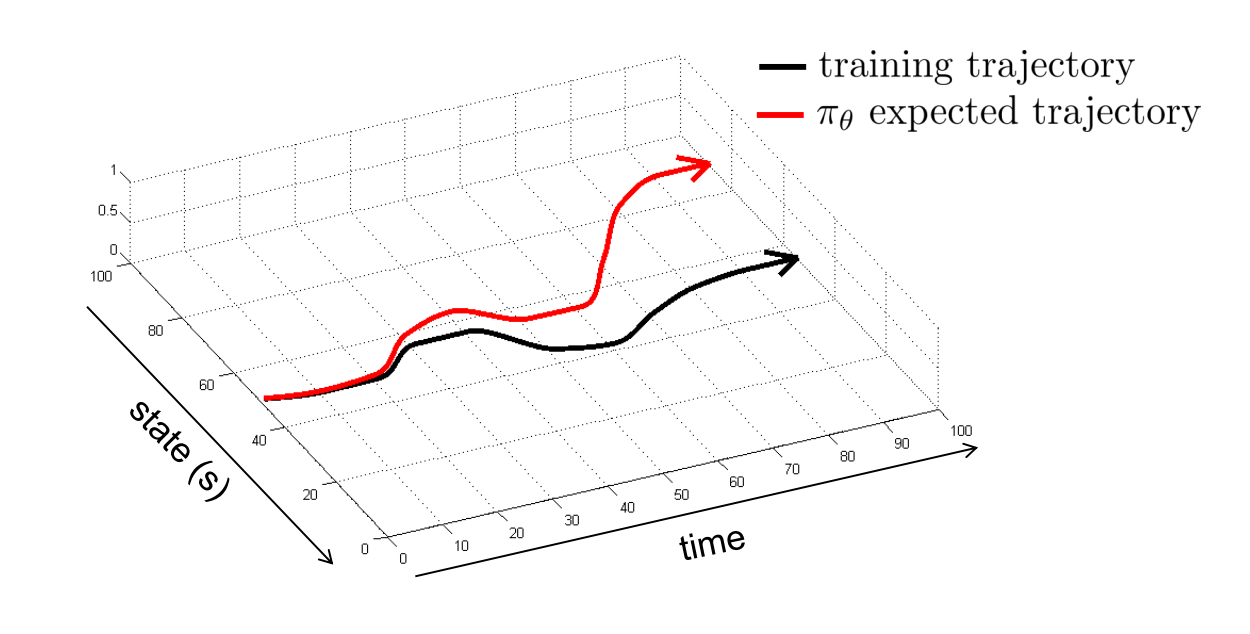
CS285 - 그래서 online RL을 사용한 fine-tuning이 필수적 (Offline2Online RL)
-
하지만 아직까지는 Gaussian policy에 대한 연구가 지배적
- Expressive policy를 효과적이고 효율적으로 fine-tuning해보자!
- 특히, Critic network 값을 최대화하도록 정책을 학습시킬 때, 행동 생성 단계에서 정책이 여러번 호출되어 back propagation이 불안정해지는 것을 해결하자.
Expressive Policy Optimization (EXPO)
표현력을 담당하는 diffusion-based base policy $\pi_{\text{base}}(a \mid s)$
-
Expressive policy는 표현력이 좋은 대신 RL로 학습시키기 어려움
⇒ Behavior cloning으로 안정적으로 학습시키자.
-
이 논문에서는 DDPM 목적함수 사용
\[\mathcal{L}(\pi_{\text{base}})=-\mathbb{E}_{(s,a)\sim\mathcal{D}, \, t\in[T], \,\bm{\epsilon}\sim\mathcal{N}} \left[ \lVert \bm{\epsilon}-\bm{\epsilon}_{\text{base}}(\sqrt{\bar{\alpha}_t}a + \sqrt{1-\bar{\alpha}_t }\bm{\epsilon},s,t)\rVert_2^2\right].\]- $T=10$
- $(s, a)$는 offline dataset에서 절반, replay buffer에서 절반 샘플링 (RLPD 기법)
RL 통한 self-improvement를 담당하는 Gaussian edit policy $\pi_{\text{edit}}(\hat{a} \mid s\color{red}{, a})$
-
Base policy가 만들어 준 행동 $a$ 근처에서 value를 최대로 만들어 줄 수 있도록 행동을 찾아주는 역할
\[\tilde{a}\leftarrow a + \hat{a},\]where $a \sim \pi_{\text{base}}(\cdot \mid s)$ and $\hat{a} \sim \pi_{\text{edit}}(\cdot \mid s,a)$.
-
Edit policy는 SAC의 목적함수를 사용하여 학습됨
\[\mathcal{L}(\pi_{\text{edit}})=-\mathbb{E}_{(s,a)\sim\mathcal{D}, \,\hat{a} \sim \pi_{\text{edit}}(\cdot \mid s, a)} \left[ Q_\phi (s, a + \hat{a}) - \alpha \log \pi_{\text{edit}}(\hat{a} \mid s, a)\right].\]- 행동 $a$ 근처에서 Q 함수를 locally maximize할 수 있는 $\hat{a}$를 학습
- 엔트로피 텀을 통해 exploration을 장려하여 base policy보다 더 optimal해질 수 있음
-
Base policy와 너무 멀어지게 학습되지 않도록 $\hat{a}$ 를 $[-\beta, \beta]$ 범위로 clipping하여 사용
- Offline 데이터셋이 좋으면 $\beta=0.05,\,0.1$ 등 작게
- Offline 데이터셋이 안 좋으면 $\beta=0.5, \, 0.7$ 등 크게
Roll-out 시 다양한 행동을 뽑아서 선택하는 On-the-fly policy $\pi_{OTF}$
- Motivation: Critic network가 업데이트된 후 정책이 업데이트된 critic network를 따라갈 때까지 시간 소요
-
업데이트된 critic network를 최대로 만들어 주는 행동을 바로 바로 선택할 수 있도록 다음과 같은 sampling-based action selection 사용
\[\pi_{\text{OTF}}(a \mid s, \pi_{\text{base}}, \pi_{\text{edit}}, Q_{\phi}):=\operatorname*{argmax}_{a\in\cup_{i=1}^{N}\lbrace a_i,\tilde{a}_i\rbrace}Q_\phi(s,a),\]where $a_i \sim \pi_{\text{base}}(\cdot \mid s)$, $\hat{a}_i \sim \pi_{\text{edit}}(\cdot \mid s,a_i)$, and $\tilde{a}_i = a_i + \hat{a}_i$ for $i=1,\ldots,N$.
- $N=8$.
-
TD target 계산에 사용되는 next action도 $\pi_{\text{OTF}}$ 사용

Experiments
Benchmarks
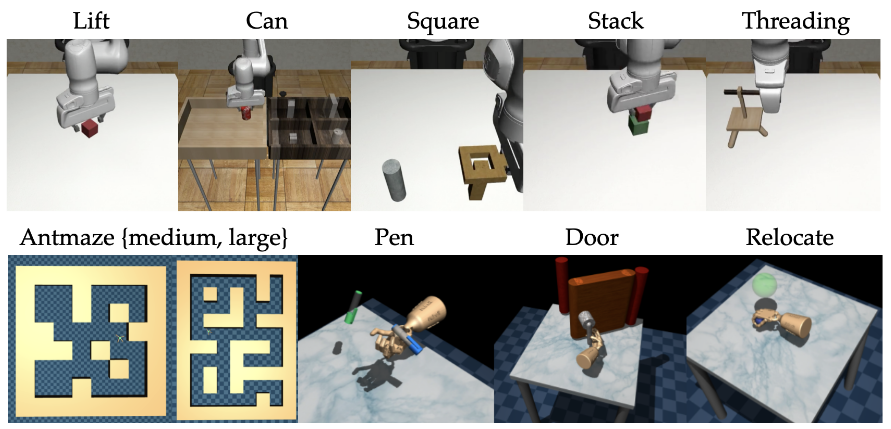
- 모두 task를 완료할 때만 보상을 주는 sparse reward 환경
- D4RL에서 Antmaze와 Androit 로봇 손
- Robomimic과 MimicGen에서 7 DoF Franka 로봇 팔
- Robomimic은 human teleoperation으로 수집한 데이터 10, 300, 200개
- MimicGen은 human 데이터 10개 + MimicGen이 생성한 데이터 190개, 40개
Baselines
불공평한 비교가 많았던 것 같음
- RLPD (offline2online)
- 미니배치 뽑을 때 offline dataset에서 50%, replay buffer에서 50% 뽑는 방법론
- cf. RLPD 이전에는 offline dataset + replay buffer에서 랜덤하게 미니배치 뽑음
- Gaussian policy 사용
- EXPO는 RLPD의 미니배치 샘플링 방법론 사용
- 미니배치 뽑을 때 offline dataset에서 50%, replay buffer에서 50% 뽑는 방법론
- IDQL (diffusion policy, offline RL, offline2online)
- IQL을 사용해서 diffusion policy를 학습시키는 방법론
- EXPO과 비교했을 때, edit policy가 없고 $\pi_{\text{OTF}}$ 를 roll-out에만 사용한 방법론
- DAC (diffusion policy, offline RL)
- online2offline 방법이 없어서 그냥 offline objective를 갖고 실험했다고 함
- QSM (diffusion policy, online RL)
- Online RL 방법론이라 fine-tuning 성능 비교에서는 제외했다고 함
- Cal-QL (offline2online)
- RLPD와 마찬가지로 Gaussian policy 사용했다고 해서 그냥 Gaussian policy 사용했을 때와 성능 비교
Offline dataset만 주어지고 policy는 from-scratch 훈련시켰을 때,
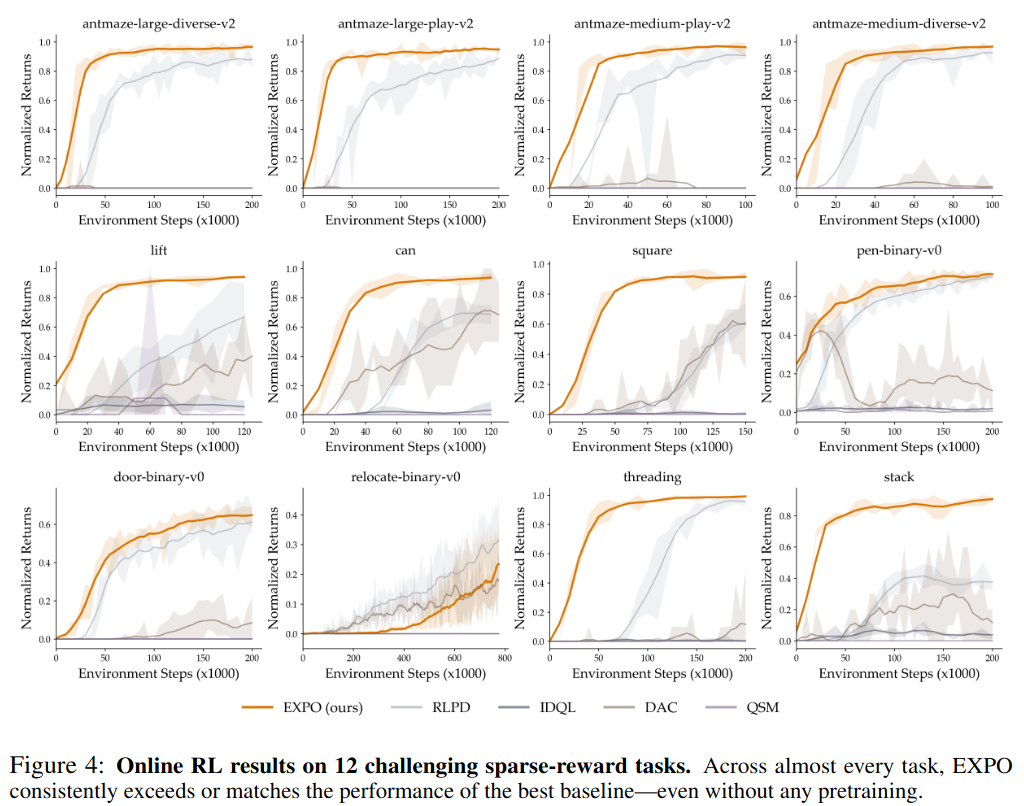
- Expressive policy를 처음부터 훈련시켜도 학습 불안정성이 없음
relocate-binary-v0환경은 데이터가 애초에 적어서 학습이 잘 안되는 환경
- 비교군들 색상 선택을 너무 비슷하게 해서 보기 안 좋음.
사전훈련된 expressive policy를 fine-tuning할 때,
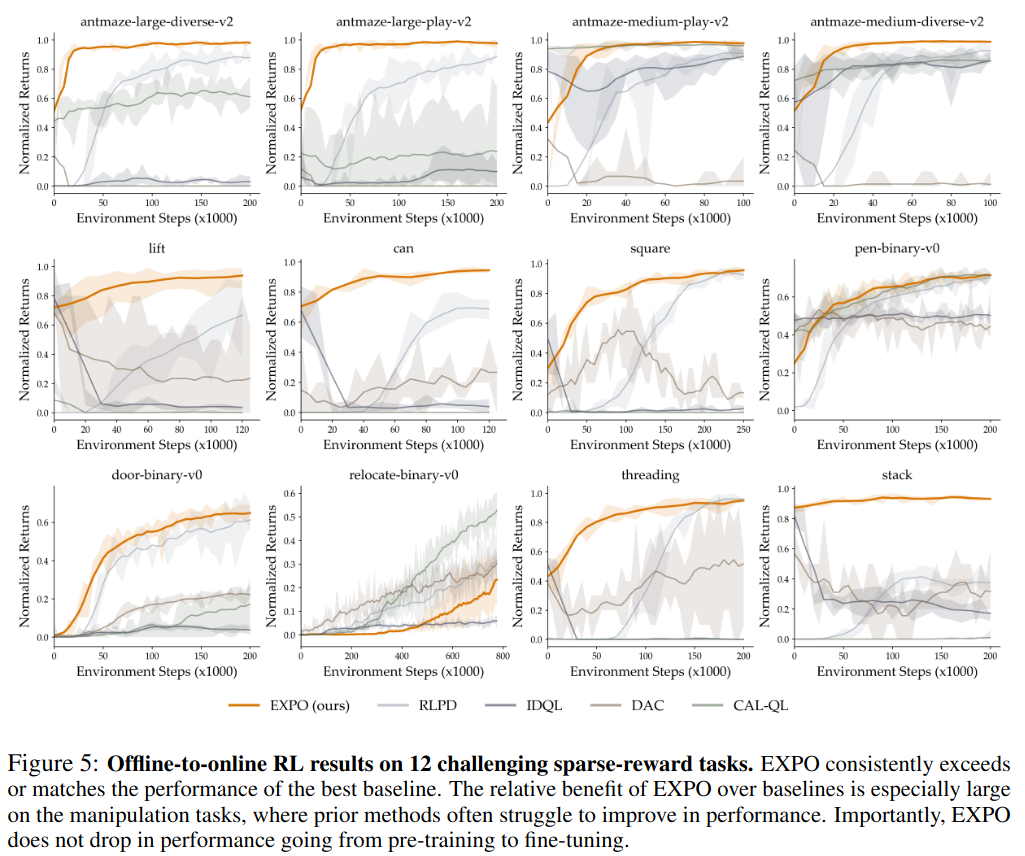
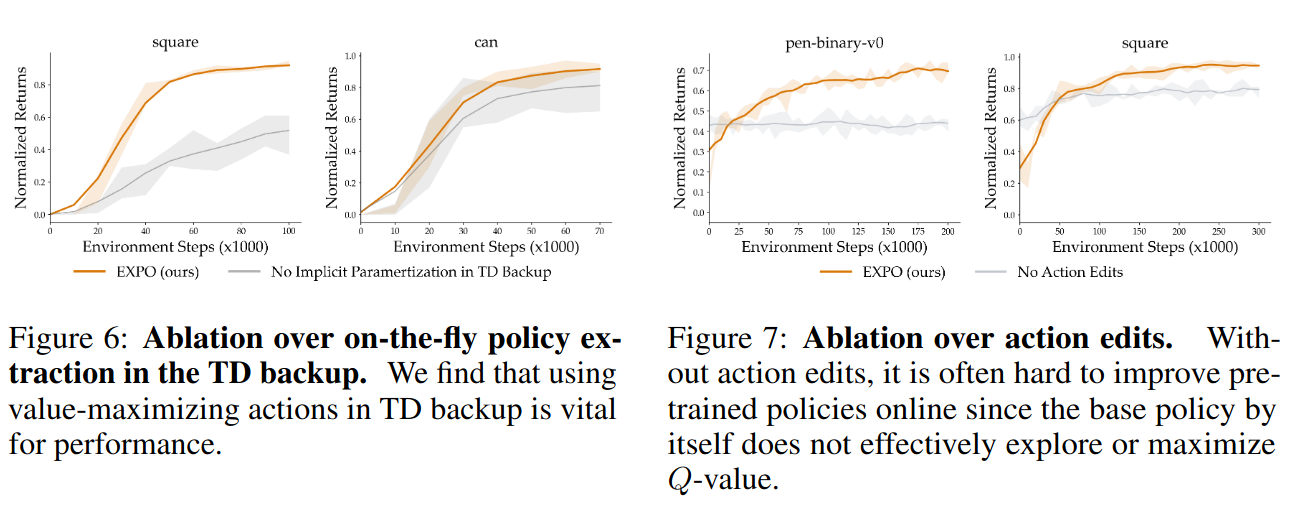
Ablation studies
Figure 6: On-the-fly policy를 roll-out에만 사용했을 때
Figure 7: Edit policy를 사용하지 않았을 때 (Figure 7)
Offline dataset 크기에 따른 최종 성능 비교
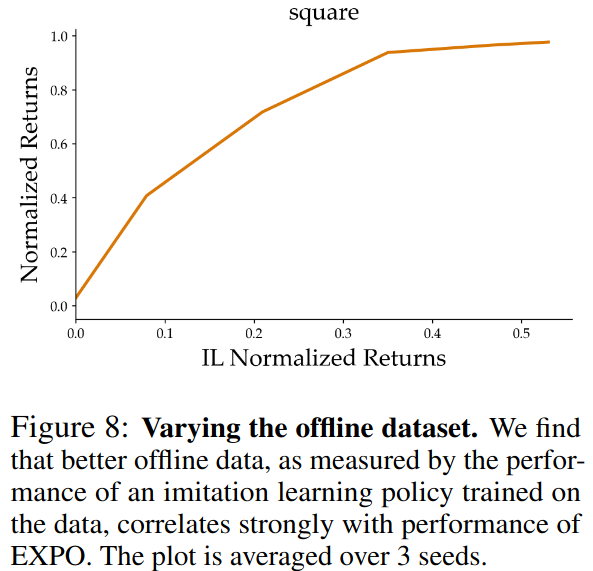
Offline dataset을 처음에 주어졌을 때