![[논문 리뷰] Planning with Diffusion for Flexible Behavior Synthesis](/assets/img/250410/image_4.png)
[논문 리뷰] Planning with Diffusion for Flexible Behavior Synthesis
작성자: 이민경
논문 정보
제목: Planning with Diffusion for Flexible Behavior Synthesis
저자: Michael Janner, Yilun Du, Joshua B. Tenenbaum, Sergey Levine, UC Berkeley, MIT
학회: ICLR 2022
1. 배경
📍기존 모델기반 강화학습의 문제점
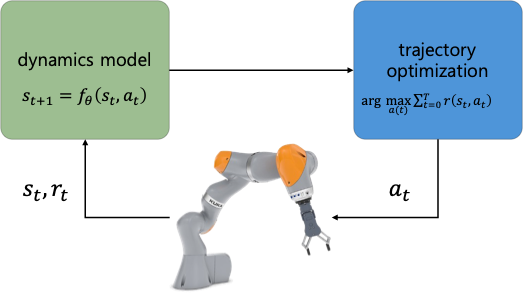
기존의 Model-Based Reinforcement Learning (MBRL)은
- Dynamics Model($f_\theta$)로 학습하고,
- Planning이나 Decision-Making은 MPC, iLQR 과 같은 전통적인 최적제어(Trajectory Optimization)방식으로
- 액션 시퀀스를 구함
- ➡️ 학습된 모델 $f_\theta$을 시뮬레이터로 사용해서, 해당 모델에 대한 최적화 알고리즘을 돌려서 $\pi^{*}(s)$ 또는 action sequence $(a_1, a_2, …)$를 찾는 방식인데.
- 📍 문제는 이 방식이 “그렇게 잘 작동하지 않는다”는 한계가 있다.
- Dynamic Model이 리얼월드를 100% 정확하게 반영하지 못한다
- 실제 보상에 최적화된 Trajectory가 아니라 그럴싸한 Trajectory를 생성한다
- 모델에서만 최적이고 실제로는 불가능한 Trajectory가 생성된다
- Adversarial Example을 만들기 쉽다
이를 해결하기 위해 기존의 MBRL 연구들은
- Model-Free 방식처럼 Value Function을 학습하거나
- Random Shooting, Cross-Entropy 같은 Gradient-Free Planning을 사용
✅ 그럼 이 논문은 어떤 아이디어로 MBRL 문제를 해결하려고 하는가
이와 같은 MBRL의 고질적인 문제를 해결하기 위해,
- Dynamics Model(동역학 예측)과 Planning(Trajectory Optimization)을 분리하지 않고,
- 플래닝 == 샘플링으로 통합한 방식을 제안
Data-driven Trajectory Optimization 방식으로, 모델에서 샘플링 하는 것과 플래닝 하는 것이 거의 동일하게 되도록 하는 것이 Diffuser의 핵심이다.
- 모델에서 샘플링하는 것 자체가 목표달성을 위한 최적의 액션을 플래닝하는 과정과 동일하게 진행
- 모델이 단순히 환경을 흉내내던 역할에서 벗어나 주어진 목표 달성을 위해 계획된 액션 궤적을 직접 생성할 수 있게 하는 것
학습된 모델에서 시퀀스를 뽑아내는 것이 원하는 Planning(최적의 액션 시퀀스)을 얻는 과정과 최대한 직결되도록 설계해서, 모델이 단순히 다음 상태를 예측하는 것이 아니라 주어진 목표/제약조건을 만족하는 계획된 액션 시퀀스를 직접 생성할 수 있어야 한다.
2. 문제정의 및 Diffusion 모델
Diffuser에서 다루는 플래닝은 Behavior Synthesis 분야에서의 Trajectory Optimization 연구를 학습(Learning) 관점에서 재해석한 것으로, (1)Trajectory Optimization에서 다루는 문제설정과 (2)이를 풀기 위해 사용할 Diffusion 모델을 간략히 소개한다.
⚙️ 문제정의
- Discrete-time Dynamics; 시스템 동역학
- 시스템은 다음 상태 $s_{t+1}$가 함수 $f(s_t, a_t)$로부터 결정되는 이산시간(discrete-time) 형태
- Trajectory Optimization 정의
- 목표는 Time Step $0 \sim T$ 까지의 행동 시퀀스 $\mathbf{a}_{0:T} = (a_0,a_1,\ldots,a_T)$ 를 찾아서
- Time Step 별 보상의 합 — $\sum\nolimits^{T}_{t=1}r(s_t,a_t)$ — 을 최대로 만드는 것
- 주어진 시스템에서 목표달성을 위해 최적의 행동 시퀀스를 찾는 과정으로 각 행동이 시간에 따라 시스템의 상태를 어떻게 변화 시키는지 고려해서 최적의 행동을 결정함
⚙️ Diffusion Model
- Iterative Denoising Process
- Forward process $q(\tau^{i}\mid\tau^{i-1})$
- 데이터(Trajectory)에 점진적으로 노이즈를 더해서 원본 데이터를 오염시켜가는 절차
- Reverse process $p_\theta(\tau^{i-1}\mid\tau^i)$
- Diffusion 모델에서 학습의 핵심
- 오염된 데이터 $\tau^i$ 를 역으로 복원(Denoise)하는 역방향 확률 분포를 모델링하는 것
- $\tau^N$ (Gaussian noise)에서 시작해서 $\tau^{N-1},\ldots,\tau^0$ 까지 반복적으로 노이즈를 제거
-
최종적으로 원본 데이터(Trajectory)를 샘플링할 수 있게 한다
\[p_{\theta}(\mathbf{\tau}^0) = \int p(\mathbf{\tau}^N)\prod^{N}_{i=1}p_\theta(\mathbf{\tau}^{i-1}\ \mid \mathbf{\tau}^i)\mathrm{d}\mathbf{\tau}^{1:N}\] - 초기분포 $p(\tau^N)$ (보통은 가우시안)로부터 샘플링한 뒤
- 모델 $p_\theta(\tau^{i-1}\mid\tau^i)$를 순차적으로 적용해서 원본 데이터($\tau^0$)로 denoising하는 과정을 전부 적분
- $\tau^0$ 를 샘플링하면, 실제 학습 데이터 trajectory와 유사한 분포에서 샘플링할 수 있다
- Forward process $q(\tau^{i}\mid\tau^{i-1})$
- 학습 목표
- Diffusion에서 — $\theta$ 를 학습한다 — 는 말은 역방향 확률분포로 노이즈를 제거하면서 원본 데이터를 복원하는 과정의 Log-Likelihood를 최대화하는 것 (= minimize negative log-likelihood)
-
이미지에서 사용되는 Diffusion과 동일하게 Variational Bound (ELBO)를 최적화하는 형태가 일반적
\[p_\theta(\mathbf{\tau}^{i-1}\ \mid\ \mathbf{\tau}^i) = \mathcal{N}(\mathbf{\tau}^{i-1}\ \mid\ \mu_{\theta}(\mathbf{\tau}^i, i),\ \sum\nolimits^{i})\] - 보통 순방향은 미리 정해진 스케줄로 고정하고
- 역방향을 파라미터화해서 KL이나 MSE 형태로 variational bound를 최소화해서 학습하는 구조
- DDPM 논문을 참고하면 좋습니다
MBRL의 문제를 풀기 위해 왜 Diffusion 모델을 차용했는가
- 멀티모달 동역학 분포 학습에 용이
- 이미지 생성분야에서 높은 품질의 샘플을 생성 (강력한 표현력)
- 특히 조건부 생성에 유연하게 대응
- 이미지에서도 로컬 디테일을 조금씩 보정하면서 전역적으로 자연스럽게 만드는 과정을 수행
- Iterative Denoising 하므로 Long Horizon 샘플링 가능
- 학습 과정이 안정적임
3. Planning with Diffusion
✅ 논문에서 제안하는 방식: Diffuser
- 학습된 Dynamics Model + 전통적인 최적제어 방식에서 벗어나서
- Sampling과 Planning을 통합하는 방식인 Diffuser를 제안
- Planning 과정을 생성모델(Diffusion) 안에 최대한 통합하는 방식
- Sampling == Planning
- ✅ Diffuser의 핵심 골자는
- Diffusion 모델을 통해 학습된 모델 분포 $p_\theta(\tau)$를 사용해 Trajectory Distribution을 학습하고
- 조건(Perturbation) $h(\tau)$를 곱한 뒤 정규화하는 조건부 샘플링으로
- $h(\tau)$는 조건을 표현하는 함수로 원본 분포인 $p_\theta(\tau)$에 곱하여 새로운 분포를 정의하고 이를 통해 Conditional Planning 또는 Goal-Conditioned Trajectory Generation을 수행
기존의 MBRL과 어떻게 다를까?
- 일반적인 MBRL은 Dynamics와 조건(보상)가 결합된 형태로 (1) Dynamics 모델로 환경 전이함수를 학습하고, (2) Planning 과정에서 보상함수와 $f_\theta$ 를 같이 사용해 Trajectory를 최적화
- Planning에서 학습된 모델을 환경 시뮬레이터처럼 쓰고, 보상함수를 명시적으로 함께 고려해서 액션 시퀀스를 탐색
- Dynamics + 보상함수가 한 덩어리로 작동해야 Planning이 진행되고
- 보상함수를 바꾸거나 새 태스크 추가하려면 Planning 알고리즘 다시 설정하거나 조정해야 함
- 정리하면,
- 물리적 타당성과 목표 성취를 동시에 반영하는 분포 $p_\theta(\tau)h(\tau)$ 에서 Sampling하는 과정이 곧 Planning이 된다는 논리로. 모델이 Dynamics만 학습하지 않고, Sampling == Planning 에 적합한 분포를 통째로 학습하고, 학습된 분포를 그대로 재사용하면서 상황에 맞춰 $h(\tau)$ 를 다르게 정의하면 쉽게 다른 태스크에도 적용할 수 있음
- Dynamics $p_\theta(\tau)$ 와 목표・보상・제약 등의 조건 $h(\tau)$ 을 분리하였기 때문에 하나의 Diffusion 모델로 다양한 태스크에서도 모델 재활용 가능
Diffuser는
- 위 내용을 구현한 Trajectory Generation용 Diffusion Model로
- 단순히 동역학을 예측하는 모델이 아니라 Trajectory 전체를 확률적으로 생성하는 모델
- 샘플링 과정에서 보상・목표・제약 등의 조건을 반영하여
- Optimal Action Sequence를 구함
- Diffusion-based Planning을 위해 두가지 기법을 적용하여 구현:
- Classifier-guided Sampling
- 이미지 생성에서 Classifier에 의해 샘플링 방향을 유도하는 기법
- Diffuser에서는 보상함수로 Trajectory 샘플을 유도하는 방식으로 적용함
- Image Inpainting
- 이미지 일부 영역을 마스킹한 뒤 복원하는 아이디어를
- Trajectory 일부 시점만 고정하고 나머지를 재생성하는 방식으로 적용함
- Classifier-guided Sampling
3.1. A Generative Model for Trajectory Planning
- Temporal Ordering
- 기존의 Dynamics는 인과구조를 전제해서 $s_{t+1}$는 $s_t,a_t$ 로부터 Autoregressive하게 예측하는 형태
- 그러나 Planning에서는 미래상태(목표상태, $s_T$ 등)를 보고 현재액션을 결정해야 됨
- $p(s_1\mid s_0, s_T)$ 처럼 과거와 미래를 동시에 봐야되는 경우가 발생
- $s_1$이 $s_T$에도 의존할 수 있음
- 따라서 시계열 전체를 한꺼번에 샘플링(예측)하는 Non-Autoregressive 접근이 필요
- 모든 timestep $0 \sim T$까지에 해당하는 상태 및 액션을 동시에 Sampling(생성)하는 모델로 설계
- Sampling == Planning 아이디어의 핵심구조
- Temporal Locality
- Non-Autoregressive라고 해도 주변 시점(앞뒤 몇 스텝) 정보가 있어야 맥락 유지 가능
-
Single Temporal Convolution을 사용해서 각 시점이 근접시점들하고만 상호작용함
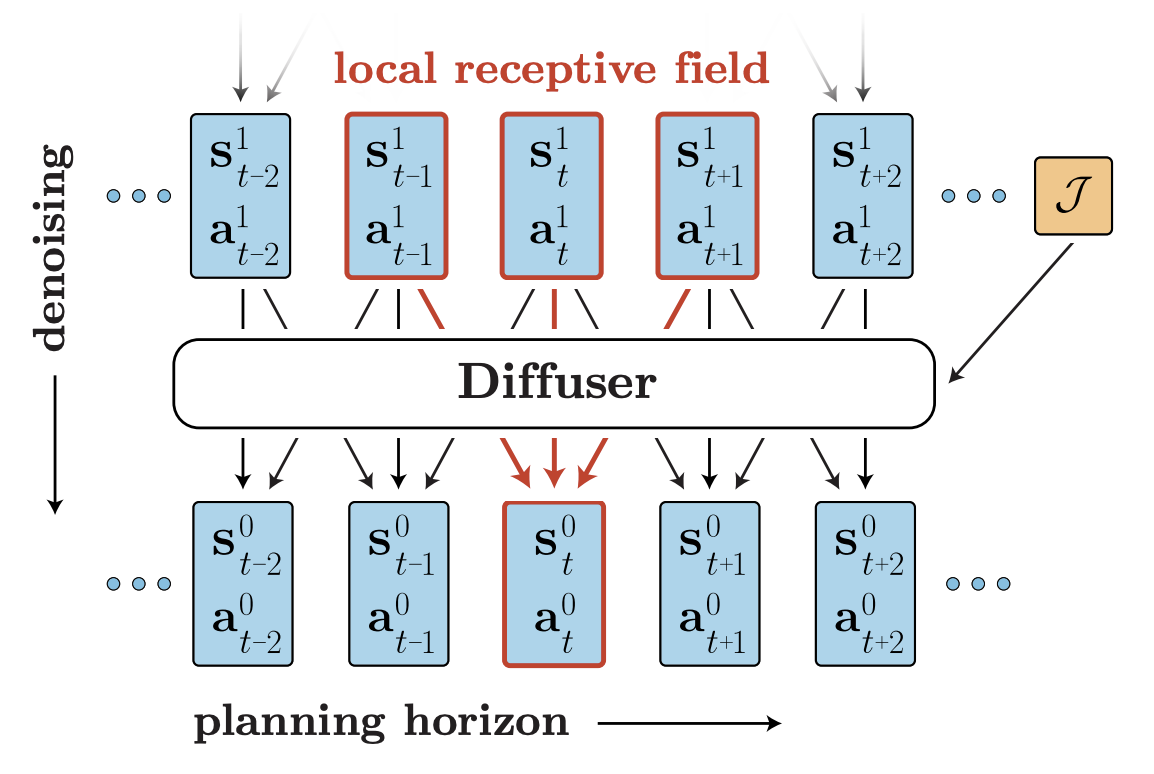
- ‘부분시점(근접 시간)만’ 보는 구조
- 이때 Diffusion의 Iterative Denoising 특징을 활용해
- 각 Denoising Step 마다 부분 인접 정보를 참조해 부분적으로 노이즈를 제거하고
- 이를 여러번 반복하여 전역적으로 자연스러운 Trajectory 얻음
- Trajectory Representation
- Diffuser는 Planning이 주목적
- 다음상태만 예측하는게 아니라 상태와 액션 전체를 하나의 시퀀스로 묶어 동시에 모델링해야함
- 액션을 바꾸면 동역학 전개가 달라지고 이는 플래닝과 연결되기 때문에 액션도 예측대상에 포함됨
- 액션도 모델 내부에서 생성
- 행$(s_t, a_t)$과 열 $T$ 형태의 2D 배열로 Trajectory를 표현하면
- 1D Temporal Convolution으로 시간축을 처리해서 전체 시퀀스를 생성
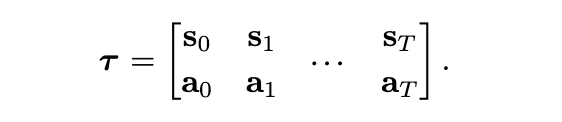
- 한 열이 시점 $t$의 $(s_t,a_t)$ 쌍을 의미하기 때문에 시계열을 열 단위로 처리할 수 있고
- Diffuser는 이 행렬을 한꺼번에 (상태, 액션) 시퀀스로 다룰 수 있음
- Architecture
- 살펴본 내용을 바탕으로 설계요건을 다시 정리하면
- 전체 Trajectory를 Non-Autoregressive하게 처리
- 각 Denoising 단계는 부분 시점에만 의존
- 시간축은 평행이동에 대한 등변성을 허용해야 되지만 (상태, 액션) 차원은 그렇지 않아도 됨
- 시간축은 순차구조, 상태・행동 차원은 그저 값으로 취급
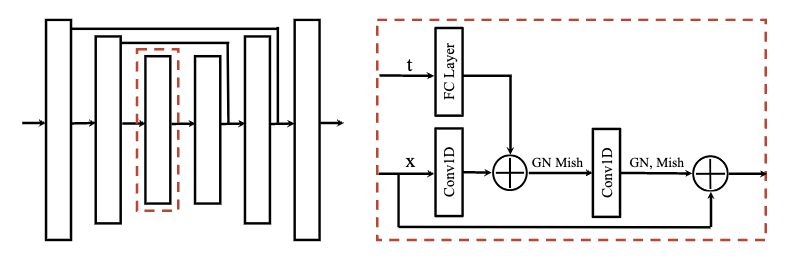
- 모델은 이미지용 Diffusion의 2D Conv U-Net을 1D Temporal Conv로 변경한 구조
- Residual Block을 반복해 시간축에 대한 패턴을 점진적으로 학습・보정 (국소 → 전역)
- Fully Convolution하므로 입력값인 Trajectory의 길이 $T$를 유연하게 변경 가능
DDPM U-Net 추가설명
- 이미지 생성에서의 Diffusion
- $H \times W$ 인 이미지를 입력받고 (Height, Width로 2D 구조)
- 2D Convolution을 사용하는 U-Net 구조로 (Downsample → Upsample)
- 노이즈가 섞인 이미지를 조금 더 깨끗하게 복원하는 단계별 처리 진행
- 여러 레벨로 다운샘플(공간 해상도 축소)하고 다시 업샘플(공간 해상도 복원)하면서 Residual(Skip Connection)으로 세부정보 보전
- 시계열로 바꿀 때 1D Convolution
- 시간축이 유일한 축이라 1D Conv
- Diffuser는 행(상태・액션), 열(시간) 2D 배열로 표현했으나
- 시간축인 열만 Conv를 적용하고 상태・액션 차원은 Feature Channel로 취급
- 다운샘플・업샘플 대신 1D Conv + Residual Block 반복을 통해 Timestep 간의 국소적인 패턴을 점진적으로 학습 및 보정 (일정한 길이 $T$에 대해 1D Conv로 필터링 반복하며 Denoising)
- 살펴본 내용을 바탕으로 설계요건을 다시 정리하면
- Training
- Diffusion 모델처럼 $\epsilon$-prediction을 사용해서
- Denoising 단계에서 필요한 평균 $\mu_\theta$ 를 $\epsilon$ 추정값에서 직접 구함
- Objective Function for Training the $\epsilon$-model :
- 모델이 $\tau^i$를 보고 추가된 노이즈 $\epsilon$ 을 얼마나 정확하게 맞출 수 있는지 학습하는 것으로
- 시계열(Trajectory) 형태이므로 1D Conv를 거쳐서 시계열 전 구간의 노이즈 추정 가능
- $\mathcal{L(\theta)}$를 최소화하면 노이즈가 섞인 Trajectory를 원본으로 Denoising하게 됨
- 공분산 $\sum\nolimits^i$ 은 Cosine Schedule에 따라 설정해 샘플링 품질 높임
DDPM $\epsilon$-prediction 추가설명
- Reverse Process $p_\theta(\tau^{i-1}\ \mid \tau^i) = \mathcal{N}(\tau^{i-1}\ ;\ \mu_\theta(\tau^i,\ i)\ \Sigma^i)$에서 직접 $\mu_\theta$ 를 예측하는 대신 $\epsilon_\theta$ 모델을 학습
- 네트워크는 $\tau^i$ 와 Diffusion Step $i$ 가 주어졌을 때, 원본 데이터 $\tau^0$ 에 추가된 노이즈 $\epsilon$ 을 추정
- 이후 이 추정값 $\epsilon_\theta(\tau^i,\ i)$ 을 사용해 $\mu_\theta$ 를 수식으로 직접 구할 수 있게 설정함
- $\epsilon$-prediction이 직접 $\mu_\theta$ 를 예측하는 것보다 더 단순하고 안정적이고 샘플링 품질도 좋음
- 학습시 실제 노이즈 $\epsilon$ 와 네트워크가 예측한 $\hat{\epsilon}$ 의 MSE 최소화로 손실함수 구현되어 단순함
- $\mu_\theta$ 는 어떻게 $\epsilon_\theta$ 에서 구하나?
- $\tau^i$ 가 $\tau^0$ + 노이즈 $\epsilon$ 의 선형조합이므로, $\tau^0 \approx \tau^0_{\theta}(\tau^i,\ i)$ 로 표현할 수 있고
- $\epsilon_\theta$ 가 $\tau^i$ 에 섞인 $\epsilon$ 을 추정하면, 여차저차 해서 $\epsilon_\theta$ + $\tau^i$ + 노이즈 스케줄로
- $\tau^i \to \tau^{i-1}$에 사용될 $\mu_\theta$ 를 구할 수 있음
- 따라서 모델이 $\epsilon_\theta$ 만 학습하면, $\mu_\theta$ 를 쉽게 재구성 할 수 있음
- $\epsilon$-prediction은 모델이 직접 $\mu_\theta$ 를 파라미터화하지 않고 입력된 노이즈 $\epsilon$ 를 예측하게 설계한 것
- 학습시엔 실제 노이즈와 예측 노이즈 간의 MSE 손실로 정의
- 실제 $\mu_\theta$ 는 $\epsilon_\theta$ 와 노이즈 스케줄 $(\alpha, \beta)$ 수식으로 유도 가능
3.2. Reinforcement Learning as Guided Sampling
- 지금까지 살펴본건 Dynamics에 대한 Trajectory ($s_t,a_t$)의 분포 $p_\theta(\tau)$ 학습 부분이었고
- 이제 앞서 살펴본 Diffuser 방법을 강화학습에 적용하려면 보상함수를 어떻게 설정하는지가 중요
- $h(\tau)$ 를 어떻게 설정하는지
- 이미지 생성에서 많이 쓰이는 Classifier-Guidance 방식과 유사하게 구현해봄
- 이미지 생성에서 Classifier-Guidance 사용하면 Class 제어하면서 샘플 생성이 가능했는데
- 이 아이디어를 강화학습의 보상함수에도 적용해서 보상이 높은 Trajectory를 샘플링하면 어떨까?
- Classifer-Guidance → Reward Predictor Guidance 로 치환해서 적용
- Control-as-Inference 방식을 차용해서 높은 보상을 갖는 Trajectory만을 확률적으로 샘플링
- Optimal Trajectory를 찾는 문제를 확률적 추론(Inference) 문제로 바꿔서 보는 접근
- 기존 강화학습과 다르게 보상을 Optimality 확률로 해석
- Optimality $\mathcal{O_t}$ 라는 랜덤변수로 TimeStep $t$ 가 최적인지 표현하고
- 보상이 큰 행동을 할수록 $\mathcal{O}_t=1$ 이 일어날 확률이 높게 설정
- “$\mathcal{O}_{1:T}=1$”
- 모든 시점에서 최적의 행동을 택했다는 의미
- 보상이 큰 Trajectory가 될 확률이 높아짐
- $\approx$ 원하는 목표 달성한 Trajectory 생성
- 학습된 모델의 순수 분포 $p(\tau)$와 $p(\mathcal{O}_{1:T}=1\ \mid \tau)$; 주어진 Trajectory가 최적일 확률을 계산하면
- 높은 보상을 가진 Trajectory에 높은 확률을 주는 Optimal Trajectory Distribution
💡- 강화학습 문제가 $\mathcal{O}_{1:T}=1$ 라는 조건 하에서 Trajectory를 샘플링하는 문제와 동일해짐
- 강화학습 맥락에서는 이 분포를 샘플링하면 보상이 높은 Trajectory를 얻을 수 있음
- 강화학습은 어떻게 높은 보상; 최적의 행동을 찾는가가 목표
- 전통적으로는 보상 최대화 최적화를 한다고 생각하나
- 여기서는 보상이 높은 Trajectory 분포에서 $\tau$ 를 샘플링 == RL 문제 해결
- $\tau$ 가 $\mathcal{O}_{1:T}=1$ 조건에서 뽑힐 수록 보상이 큰 액션 시퀀스
- ✅ 제어(강화학습)를 추론(샘플링)으로 본다 ⇒ Control-as-Inference 핵심
- Sampling is Reinforcement Learning and Generative Modeling is Imitation Learning (윤상웅 박사님 SNU・UCL)
- Diffuser에서의 Guided Sampling
- 학습된 분포 $p_\theta(\tau)$ 에서 Trajectory $\tau$ 를 샘플링하되
- 보상(Optimality)을 반영해서 높은 보상을 가진 Trajectory를 뽑아내고자 함
-
이를 조건부 샘플링 관점에서 접근해보면
\[\tilde{p}_\theta(\tau)\propto p_\theta(\tau)\cdot h(\tau) = p_\theta(\tau) \cdot p(\mathcal{O}_{1:T}=1\ |\ \tau)\]- 조건 $h(\tau)$ 는 Trajectory $\tau$ 가 최적일 확률, 누적 보상 $\exp(\sum r)$ 과 관련
- 조건 $h(\tau)$ 는 Trajectory $\tau$ 가 최적일 확률, 누적 보상 $\exp(\sum r)$ 과 관련
- Diffusion 모델 Denoising을 할 때 Classifier-Guidance와 유사하게 접근
- 역방향 분포 $p_\theta(\tau^{i-1}\ \mid \tau^i)$ 을 가우시안 형태 $\mathcal{N}(\mu, \Sigma)$로 근사하는데
- 최적도 $\mathcal{O}_{1:T}=1$ 조건을 추가하면서, 평균에 $\Sigma\cdot g$ 가 더해진 형태로 근사
- $g$는 누적 보상의 그레디언트를 샘플링 시점에 사용하는 것
- 이미지에서 Classifier가 클래스에 대한 로그확률 $\log p(\text{class}\mid\mathbf{x})$을 주고
- 그 그레디언트를 이용해 $\mathbf{x}$ 를 업데이트 → 클래스 이미지 구함
- 이와 유사하게 최적도에 대한 로그확률 그레디언트 $\nabla_\tau\log p(\mathcal{O}_{1:T} \mid\tau)$로
- Trajectory를 업데이트 보상 함수를 예측 → 보상이 높은 Trajectory 얻음
- 해당 보상함수의 그레디언트를 통해 샘플링 유도
- 샘플링과정에서 $\mu$ 에 보상 그레디언트를 더해주면 더 높은 보상을 향해 Trajectory를 수정
- 역방향 분포 $p_\theta(\tau^{i-1}\ \mid \tau^i)$ 을 가우시안 형태 $\mathcal{N}(\mu, \Sigma)$로 근사하는데
- Diffuser는 학습분포x최적도함수 형태로 조건부 샘플링을 수행하고 이 과정을 Denoising 단계에서 Classifier Guidance와 동일하게 보상 그레디언트를 더하는 식으로 구현해 보상이 높은 Trajectory를 얻음
- Diffuser는 상태·행동 시퀀스를 학습해서 물리적으로 타당한 Trajectory 분포 $p_\theta(\tau)$를 생성
- 보상 예측 모델 $\mathcal{J}_{\phi}$ 은 Trajectory를 입력 받아 누적 보상을 예측하여
- 파라미터 $\phi$ 로부터 $\nabla_\tau\mathcal{J}_{\phi}(\tau)$ 를 구함
- 샘플링 시 $\mu$ 에 $\Sigma \times$(보상 그래디언트)를 더해주어 보상이 높은 Trajectory를 생성
- 이렇게 샘플링된 Trajectory $\tau$ 에서 첫번째 행동을 환경에 실제로 적용하고
- 새로 관측된 상태에서 다시 반복하는 Receding-Horizon 방식으로 Planning 루프 동작
3.3. Goal-Conditioned RL as Inpainting
- Goal-Conditioned RL처럼 어떤 Planning 문제는
- 보상 극대화 보다 특정 조건을 만족하는데 더 초점을 둘 수 있음
- 최종 시점에 특정 위치에 있어야 한다, 중간에 어떤 상태·행동은 금지 등등
- 이때 어떤 목표나 제약을 만족하는 Trajectory를 찾는 문제를
- 이미지 생성의 인페인팅 기법과 유사하게 볼 수 있음
- Trajectory에서 이미 관측된 부분(목표상태, 제약 등)은 고정하고
- 나머지를 Diffusion으로 샘플링해서 전체 Trajectory가 자연스럽게 연결되게 함
- 이미지에서 관측된 픽셀은 그대로 두고 빈 영역(마스킹)을 채우는 인페인팅과 같은 접근 방식
- 핵심은 목표 또는 제약에 해당하는 부분은 바꾸지 않고 미지의 영역만 모델이 생성하되
-
전체 Trajectory가 그 목표 또는 제약에 부합해야 함 (조건부 샘플링)
\[h(\tau)=\delta_{\mathbf{c}_{t}}(\mathbf{s}_0,\mathbf{a}_0,\ldots,\mathbf{s}_T,\mathbf{a}_T) = \begin{cases} +\infty & \text{if}\ \mathbf{c}_t = \mathbf{s}_t \\ 0 & \text{otherwise} \end{cases}\]- 시간 $t$ 에 상태 $s_t$ 가 특정 값 $c_t$ 와 같다면, 즉 주어진 조건을 만족한다면, $+\infty$ 그렇지 않다면 0으로
- 샘플링할 때, $\tau$ 중 해당 시점(또는 행동)이 $\delta$-함수 조건을 만족하지 않으면 샘플링 불가
- 제약조건에 어긋나는 Trajectory는 배제되고 만족하는 Trajectory만 남음
- 샘플링 중 고정해야할 값을 직접 덮어쓰는 식으로 구현하고 모델은 나머지 고정되지 않은 영역만 Denoising으로 보정해서 전체 시퀀스를 자연스럽게 만듦
- 고정된 부분 (start state, goal, constraints 등)은 유지되고, 나머지 시점만 유연하게 Planning 됨
- 보상을 최대화하는 작업에서도 인페인팅이 필요
- 현재 환경에서 시작 상태 $s_0$ 은 이미 결정된 값이라 모델이 바꾸면 안됨
- 인페인팅 기법으로 시점 0의 상태는 고정해야 실제 환경의 상태와 일치하는 Trajectory 얻을 수 있음
4. Analysis & Experiments
Diffusion Planners 분석
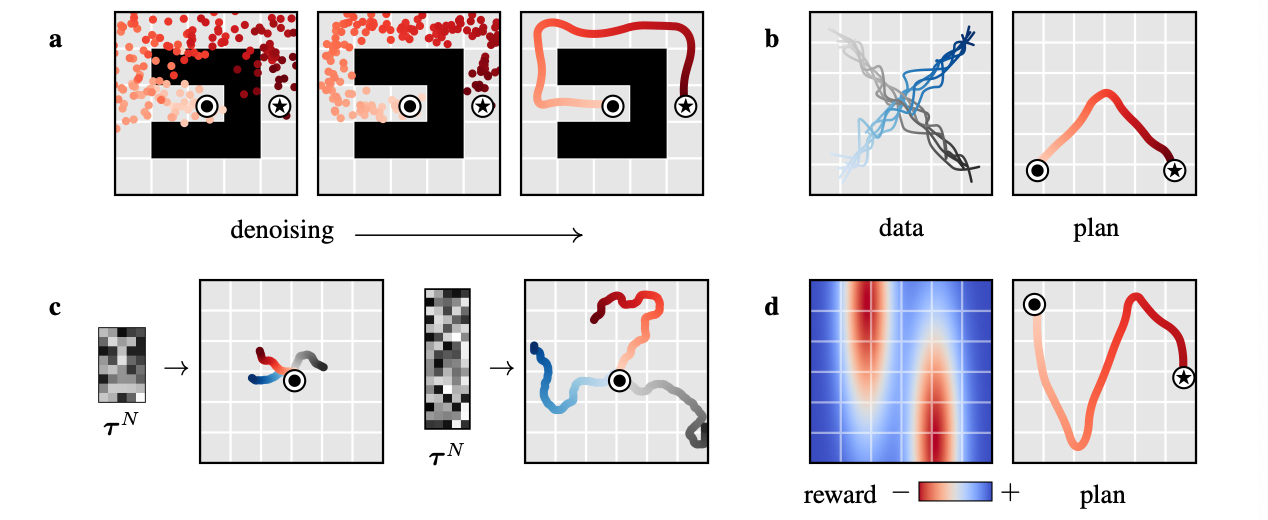
Learned Long-Horizon Planning
- Diffusion 모델이 전체 Trajectory를 한꺼번에 생성하기 때문에
- Long Horizon까지 고려하면서 Trajectory 생성하기 쉽고
- 보상이 희소해도 모델이 데이터 분포를 토대로 일관적인 행동을 샘플링 할 수 있음
Temporal Compositionality
- Diffuser는 Markovian 가정없이 반복적으로 Denoising하는 방식으로
- ‘부분적 일관성’을 점차 확장해서 전역적으로 자연스러운 Trajectory를 생성
- 이를 토대로 학습 데이터에 있는 부분 Trajectory들을 Stitching하여
- 학습 시 없던 Trajectory도 부분 Trajectory들을 토대로 생성할 수 있음
Variable-Length Plans
- Diffuser는 Fully Convolution 구조를 시간축에 적용해서 입력 노이즈 길이를 자유롭게 조절할 수 있음
- 이는 플래닝 Horizon 자체가 사전에 고정되지 않고
- Inference 시점에 원하는 시퀀스 길이를 넣으면
- 그에 맞게 Trajectory를 생성할 수 있다는 의미
- 50-step, 100-step 등 원하는 길이를 지정해도 아키텍처 변경 없이 가능
Task Compositionality
- Diffuser는 Dynamic과 행동 패턴을 학습한 생성모델일 뿐
- 어떤 보상을 최대화하라는 명령은 없는데
- 대신 플래닝(샘플링)시에 보상함수를 반영해서 목표를 달성하는 Trajectory를 뽑아냄
- 따라서 훈련 시 주어지지 않은 다양한 태스크(보상함수)들도 샘플링 단계에서 유연하게 반응할 수 있음
실험 및 성능평가
Diffuser의 강화학습 및 데이터 기반 플래닝 성능 테스트
- Long Horizon에서의 플래닝 능력
- Sparse Reward, No Reward Shaping
- 새로운 Goal에 대한 일반화 능력 (Multi-Task)
- 이질적인 데이터에서 학습된 Controller의 회복
1) Long Horizon Multi-Task Planning
- Maze2D 환경에서 Lon Horizon Planning과 Multi-Task 성능을 실험한다.
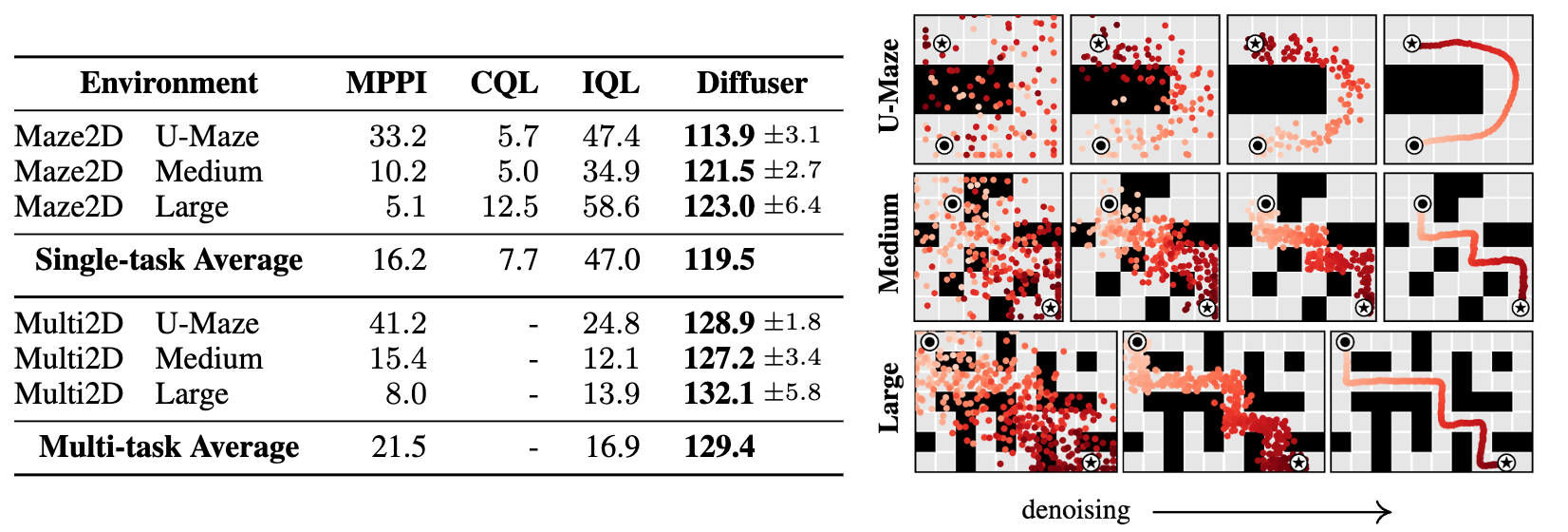
Maze2D 환경
- 에이전트가 목표지점까지 이동해야 하고. 보상은 목표지점에 도착했을 때만 1을 주고
- 중간에는 별도의 보상이 없는 Sparse Reward 구조
- 목표가 멀리 있을 수록 이동해야 되는 스텝 수가 증가하므로
- Long Horizon Credit Assignment가 어려워 기존 모델프리 RL에서는 어려운 문제
- Diffuser
- 시작위치(O)과 목표위치(★)를 미리 고정하고(inpainting)
- 나머지 상태는 Diffusion Sampling으로 채움
- 샘플링으로 얻은 Trajectory를 한 번에 전부 생성하는 Open-loop로 실행
- 중간에 다시 플래닝하지 않고 샘플된 경로 그대로 따라가게 함
- → 한번의 플래닝으로 얼마나 좋은 행동 시퀀스 뽑아내는지 보여줌
- Open-loop 방식
- 한번에 전체 Trajectory 미리 정해 놓고 실행과정에서 환경의 피드백 (실제 상태변화)을 보지 않고 그대로 수행하는 것을 의미.
- ↔ Close-loop : 매 시점 혹은 일정 주기로 실제 환경 상태를 다시 관측하고, 그에 따라 Trajectory을 재계산하거나 업데이트 하는 방식. 안정적인 방식.
- Open-loop 방식
- Multi-Task 실험 : 매 에피소드 초기에 Goal 위치를 임의로 새로 설정해서 진행
- 똑같은 모델로 시작상태와 목표상태만 바꿔주면 (=조건만 변경하면)
- 다양한 목표에서 재학습 없이 플래닝이 가능하다는 것을 입증
2) Test-time Flexibility
- Block Stacking과 Block Rearragement 실험
- Diffuser가 새로운 목표나 변경된 조건에 얼마나 유연하게 대응하는지 테스트
- https://diffusion-planning.github.io/
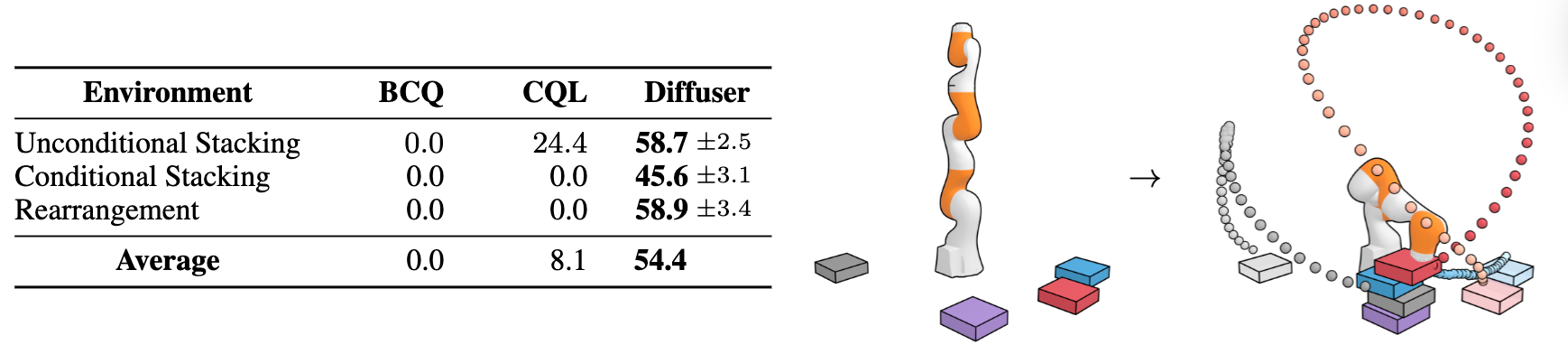
Block Stacking 설정
- KUKA 로봇이 여러 개의 블록을 조작해서 특정 목표 상태를 달성하는 태스크
- 3가지 시나리오:
- Unconditional Stacking: 제약/조건 없이 최대한 높이 블록 쌓기
- Conditional Stacking: 특정 순서대로 블록 쌓기
- Rearrangement: 주어진 레퍼런스 위치에 블록들을 재배치 하기
- 데이터셋
- PDDLStream으로 생성한 10000 Trajectories 데모데이터셋
- 보상은 블록 올바르게 쌓으면 1, 아니면 0
- 목표
- 테스트 시점에서 새로운 조건이 주어져도 잘 대응해야 되고
- 실행 과정 중 학습할 때 보지 못했던 상태를 만나도 동작이 가능해야 함
- 3가지 태스크에서 동일한 파라미터 $\theta$
- 하나의 Diffuser 모델을 사용했고
- 각각의 태스크 별로 $h(\tau)$만 다르게 설정해서 실험을 진행 (조건부 샘플링)
- (Conditional Stacking & Rearragement)
- 새로운 목표나 복잡한 조건이 적용된 경우 → Diffuser 성능이 월등
- Diffuser는 하나의 모델을 학습한 뒤
- 상이한 조건(목표, 접촉, 최종 상태 등)만 변경하는 식으로
- 다양한 태스크 요구사항에 대응할 수 있음 입증
3) Offline Reinforcement Learning
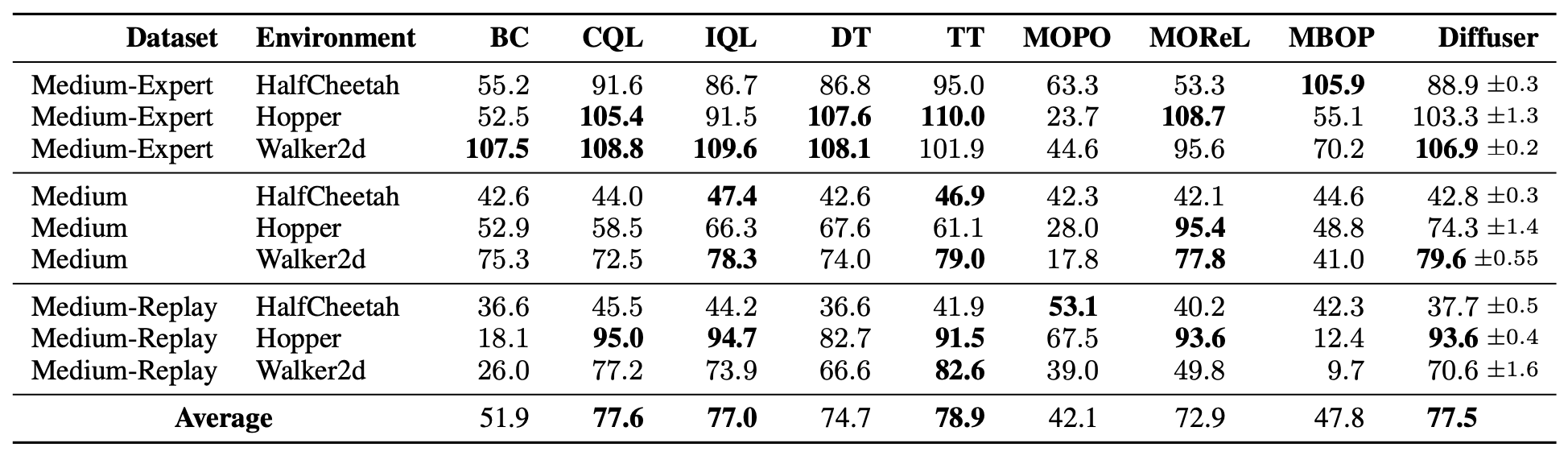
- 상태-행동 데이터의 퀄리티가 제각각인 이질적 데이터 환경을 토대로 Diffuser가 얼마나 정책을 잘 학습하는지 평가하는 것이 목적인 실험.
OfflineRL 환경에서 테스트한 Diffuser
- 보상 예측 모델로부터 얻은 그레디언트를 반영해
- 높은 보상을 가진 Trajectory 쪽으로 샘플링을 끌어가고
- 현재 상태를 모델이 임의로 바꾸지 못하도록 샘플링 시점에 고정해두고
- 나머지를 생성하는 식으로 한단계씩 플래닝을 진행함
- Diffuser가 학습된 오프라인 Trajectory 데이터와 같은 데이터로 보상 예측 모델 $\mathcal{J}_\phi$ 학습
- $\mathcal{J}_\phi$ 그레디언트가 보상이 높은 Trajectory 방향으로 샘플링을 유도
- 결과보면 성능이 좋다고 평가하기 어렵다
- 성능이 비슷하거나 약간 우세한 경향이 많음
- OfflineRL에서 CQL, IQL, TT 등의 SOTA들과 성능이 비슷
- 단일 태스크에 특화된 기법들과 비교하면 약간 성능이 저하되는 양상을 보임
- Diffuser는 단순히 예측 정확도가 좋은 모델이 아니라
- 학습된 모델을 그 자체로 샘플링(생성, 플래닝) 과정에 사용하는 점에서 의의가 있음
4) Warm-Starting Diffusion for Faster Planning
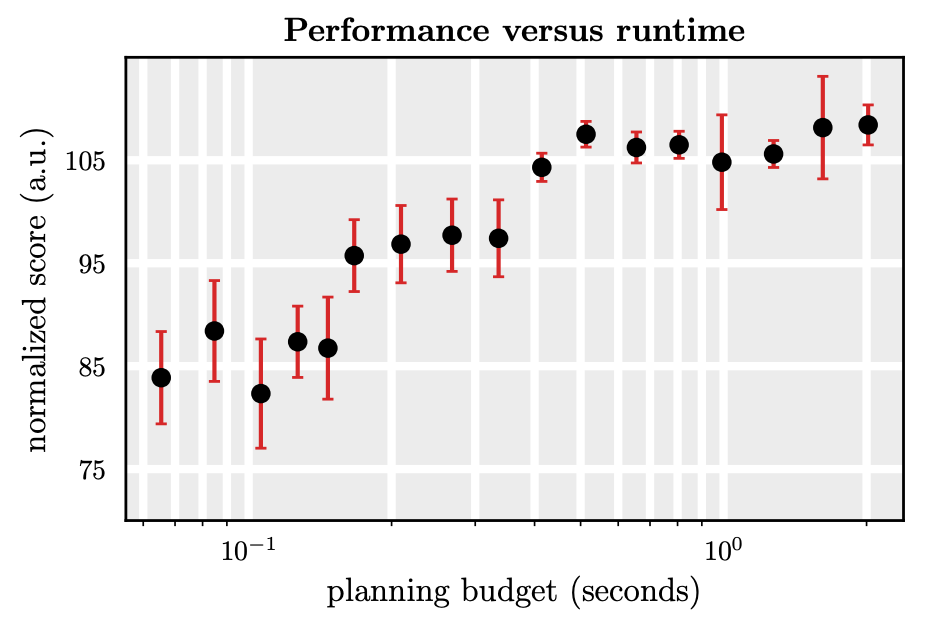
- Diffusion 모델은 여러 단계에 걸쳐서 노이즈를 점진적으로 제거하다보니 연산량이 많음
- 만약 매 timestep마다 새롭게 전체 Trajectory 샘플링해서 플래닝하려면
- 여러번 Denoising해야하므로 매우 느려지게 됨
- 이미 한 번 완성된 Trajectory가 있다면 다음 스텝에도 완전히 새로 샘플링을 할 필요가 없음
- 다음스텝은 노이즈 상태에서 시작하지 않아도 됨
- 대신 이전 플래닝을 살짝 노이즈화한 뒤에 그만큼만 Denoising하면
- 최종 샘플링이 이전 결과를 이어받은 업데이트된 Trajectory가 됨
- 계산량도 줄고 퀄리티도 어느정도 유지할 수 있게 됨
6. 논문의 의의
- 전통적인 모델기반 RL의 방식에서 벗어나 샘플링과 플래닝을 결합한 방식을 제안함.
- 하나의 확산모델 안에서 조건부 샘플링만으로 목표에 맞는 Trajectory를 생성하는 방안을 고안해냄.
- 확산모델(Diffusion)을 강화학습에 적용한 최초의 연구
- 해당 논문 이후로 DiffusionPolicy, Diffusion-QL 등 확산모델을 강화학습에 적용한 연구들이 활발해짐