![[논문 리뷰] DAPO: An Open-Source LLM Reinforcement Learning System at Scale](/assets/img/260212/image_10.png)
[논문 리뷰] DAPO: An Open-Source LLM Reinforcement Learning System at Scale
작성자: 민예린
논문 정보
제목: DAPO: An Open-Source LLM Reinforcement Learning System at Scale
저자: Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, Wei-Ying Ma, Ya-Qin Zhang, Lin Yan, Mu Qiao, Yonghui Wu, Mingxuan Wang.
학회: NeurIPS 2025
1. Introduction
Background
- OpenAI의 o1, DeepSeek의 R1 처럼 추론 시점에 연산을 늘려 성능을 올리는 방식이 (test-time scaling) 많이 사용됨
- Test-time scaling 은 더 긴 Chain-of-Thought (CoT) 추론을 가능하게 함
- 정교한 추론을 유도하여 수학, 코딩 등에서 성능이 좋음
CoT / Reasoning
CoT (Chain-of-Thought)
- 생각을 단계적으로 나열하는 구조
- 예: 삼단 논리처럼 1 → 2 → 3 → 답
- few-shot prompting / SFT 만으로도 충분히 가능
- 학습 데이터에 “단계적 설명”이 들어가 있으면 됨
- 그렇기 때문에 한 번 정한 논리의 흐름을 되돌리거나 수정하지는 못함 (정답으로 학습)
Reasoning
- 추론하는 과정 전체로 CoT를 포함하는 더 큰 개념이라고 이해함
- 마치 사람이 생각하는 것처럼 생각 -> 점검 -> 수정의 반복이 가능함
- 수정을 하려면 추론 과정에 대한 평가가 필요
- 평가가 결국 RL과의 연결 지점
- RL처럼 문제 정의하기 쉬움 (아래는 예시임)
- 상태(state): 지금까지의 추론 내용
- 행동(action): 다음 추론 스텝 / 되돌림 / 다른 가정 시도
- 평가(evaluation): 이 방향이 맞는지?
- self-verification(자기 검증)과 iterative refinement(반복적 개선) 같은 프로세스로 복잡한 리즈닝 과정을 이끌어 낼 수 있으나, 공개된 리즈닝 모델들의 자료들로는 "성능 재현"의 어려움이 있음
- 본 논문에서는 알고리즘, 학습 코드, 데이터셋을 공개하여 오픈소스로 제공하고자 함
- AIME 2024에서 50점을 달성했고, DeepSeek R1 보다 training steps를 50% 감소시킴
Contributions
1. Clip-Higher, which promotes the diversity of the system and avoids entropy collapse
2. Dynamic Sampling, which improves training efficiency and stability
3. Token-Level Policy Gradient Loss, which is critical in long-CoT RL scenarios
4. Overlong Reward Shaping, which reduces reward noise and stabilizes training
2 Preliminary
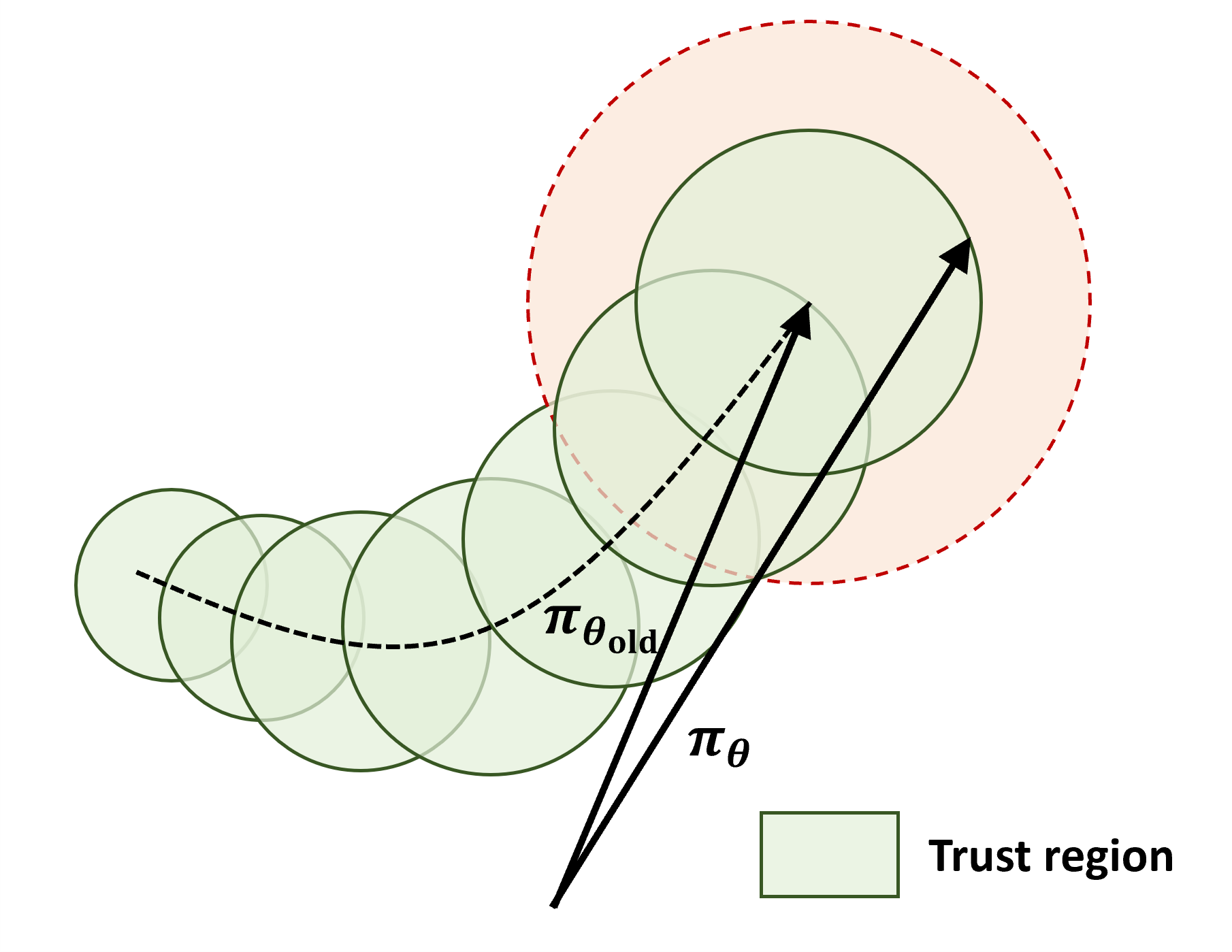
DAPO는 GRPO 를 기반으로 하고, GRPO 는 PPO를 기반으로 함
2.1 Proximal Policy Optimization (PPO)
- PPO는 policy optimization을 위해 clipped surrogate objective function를 사용함
-
Clipping 을 통해서 policy update 영역을 근접 영역으로 제한함으로서 학습을 안정화하고 샘플 효율성을 올렸음
-
- Objective function 형태
- (q, a)는 Dataset D 에서 샘플링된 (question, answer) 쌍
- $\varepsilon$은 clipping 범위
- $\hat A_t$는 advantage 추정치
- Advantage 는 value function V 와 reward function R이 존재할 때, GAE(Generalized Advantage Estimation) 를 통해 계산됨
where,
\[\delta_l = R_l + \gamma V(s_{l+1}) - V(s_l), \quad 0 \le \gamma, \lambda \le 1. \tag{3}\](델타는 TD Error, gamma는 discount factor, lambda는 GAE 파라미터)
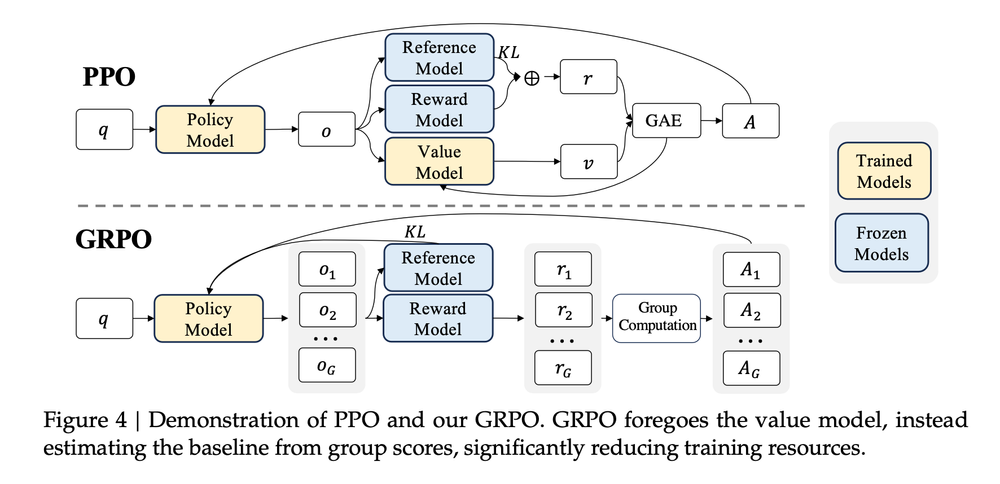
2.2 Group Relative Policy Optimization (GRPO)
- GRPO와 PPO의 차이
- Value function 을 제거하고 group-relative 방식으로 advantage 를 추정
- KL 패널티 추가
- 샘플 단위 objective update
- Advantage 계산 방식
- (q, a) 쌍에 대해 old policy 로 G개의 개별 응답을 샘플링 진행 $\lbrace o_i \rbrace_{i=1}^G$
- 즉, 동일한 질문 q의 G개의 LLM 응답을 생성
- reward function (또는 model)을 활용하여 각 응답에 대한 reward 계산
- ex. 정답이면 1, 오답이면 0
-
각 응답에 대한 Advantage 계산 : 현재 응답이 같은 질문에서 나온 다른 응답들보다 얼마나 나았는가 / 못했는가를 평가
\[\hat{A}_{i,t} = \frac{ R_i - \text{mean}\left(\{R_i\}_{i=1}^{G}\right) }{ \text{std}\left(\{R_i\}_{i=1}^{G}\right) }\]
- (q, a) 쌍에 대해 old policy 로 G개의 개별 응답을 샘플링 진행 $\lbrace o_i \rbrace_{i=1}^G$
-
objective function 형태

- PPO와 동일하게 clipped objective 사용하고 KL 패널티 항이 추가됨
- GRPO는 objective 를 sample 단위로 계산한다는 점에서 차이가 있음 (3.3 에서 설명)
2.3 Removing KL Divergence
- reference policy 와 online policy의 발산을 제어하기 위한 장치
- 모델이 초기 모델에서 지나치에 벗어나지 않도록 제어
- 하지만 reasoning 단계 중 모델 분포가 초기 모델과 크게 달라지는 경우도 있기 때문에, 본 논문에서는 KL 페널티를 제거함
- 뇌피셜 : 기존 결과를 수정하는 작업을 하기 위해서는 초기 모델과 어느 정도 달라져야 하기 때문인가?
2.4 Rule-based Reward Modeling
- reward model 을 사용하는 방식은 일반적으로 reward hacking 이 취약하다고 함
- 따라서 verifiable task의 최종 정확도를 아래 rule 에 따라 직접 사용함
- y : 정답, y hat : 모델 예측한 답
- 수학, 코딩 등 답이 명확한 케이스의 경우 비교 가능
3. DAPO
- 본 논문에서는 Decoupled Clip and Dynamic sAmpling Policy Optimization (DAPO) 알고리즘을 제안
- GRPO 처럼 (q, a)에 대해 각 질문마다 G개의 응답을 샘플링하고 아래 objective function으로 최적화 진행
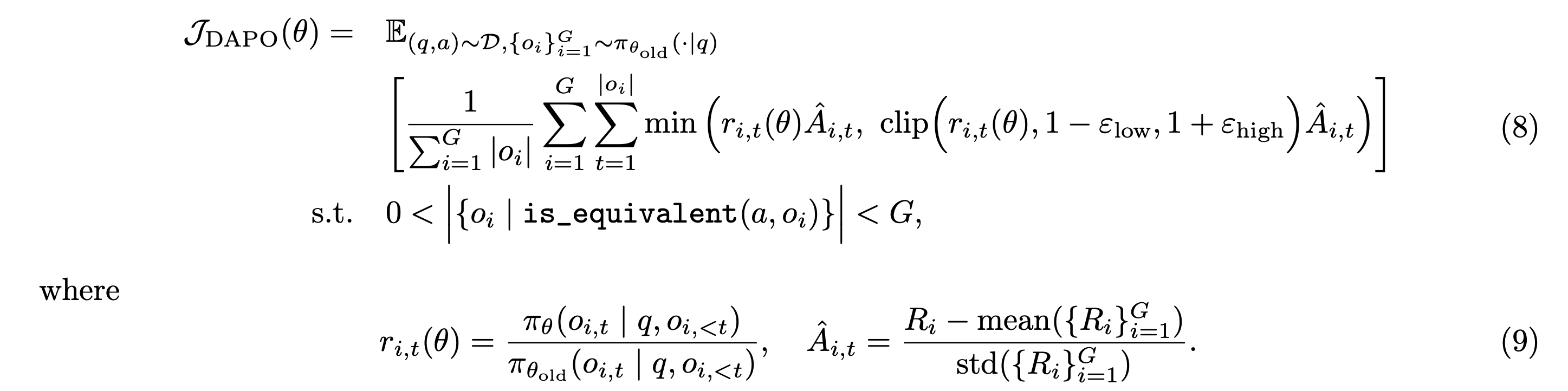
3.1 Raise the Ceiling: Clip-Higher
- naive PPO, GRPO를 사용한 초기 실험에서 entropy collapse 현상 관찰됨
- 학습이 진행됨에 따라 entropy가 빠르게 감소
- 특정 그룹의 outputs이 거의 동일해지는 경향
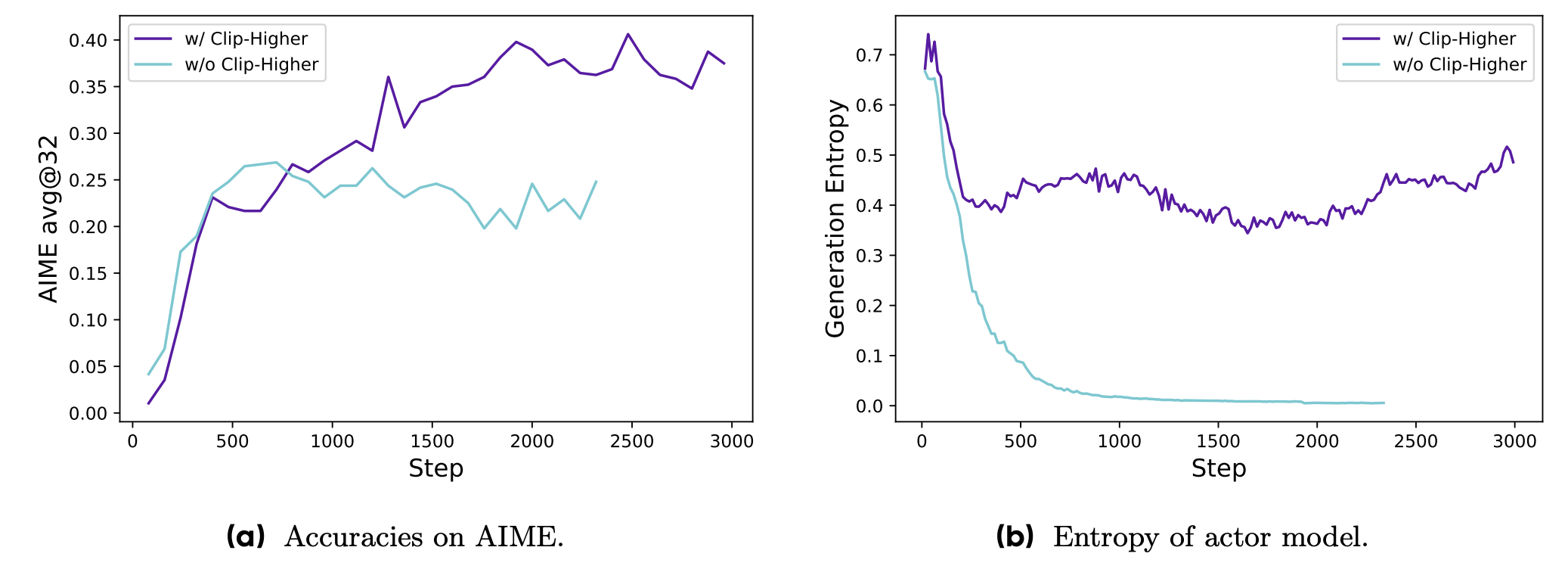
- 이러한 문제를 해결하기 위해 Clip-Higher 전략을 제안
- 목적 : ε 의 상한과 하한을 각각 다르게 지정. 상한을 더 늘려서 exploration 을 강화하고 entropy collapse를 완화
-
Clip 을 이용해 policy update 의 정도를 조절할 수 있음
\[r_t(θ)=\frac{π_θ(a_t∣s_t)}{π_{θold}(a_t∣s_t)}\]- $r_t>1$ → new policy가 이 action의 확률을 키우고 있음
- $r_t<1$ → new policy가 이 action의 확률을 줄이고 있음
-
ε의 상/하한을 분리해 상한만 늘리는 방향을 제안
- ε의 하한을 늘리면, 나쁜 토큰의 확률이 빠르게 0으로 수렴하면서 diversity 를 소실할 위험이 있음
- ε의 상한만 올리면, 좋았던 행동을 더 강화하는 방향으로 학습. 운 좋게 좋은 행동을 만나면 무시하지 않고 더 많이 강화할 수 있음
3.2 The More the Merrier: Dynamic Sampling
- 제안 : G개 샘플의 $is\_equivalent(a,o_i)$ 가 모두 0이거나 1인 샘플은 제거함 (over-sample and filter)
- 이유
- 생성된 모든 출력이 정답이거나 동일한 보상을 받으면 해당 그룹의 advantage 는 0이 됨
- advantage가 0이 되면, gradient 또한 0이 되며, batch gradient의 noise 민감도를 증가시켜 샘플 효율성이 떨어지게 됨
-
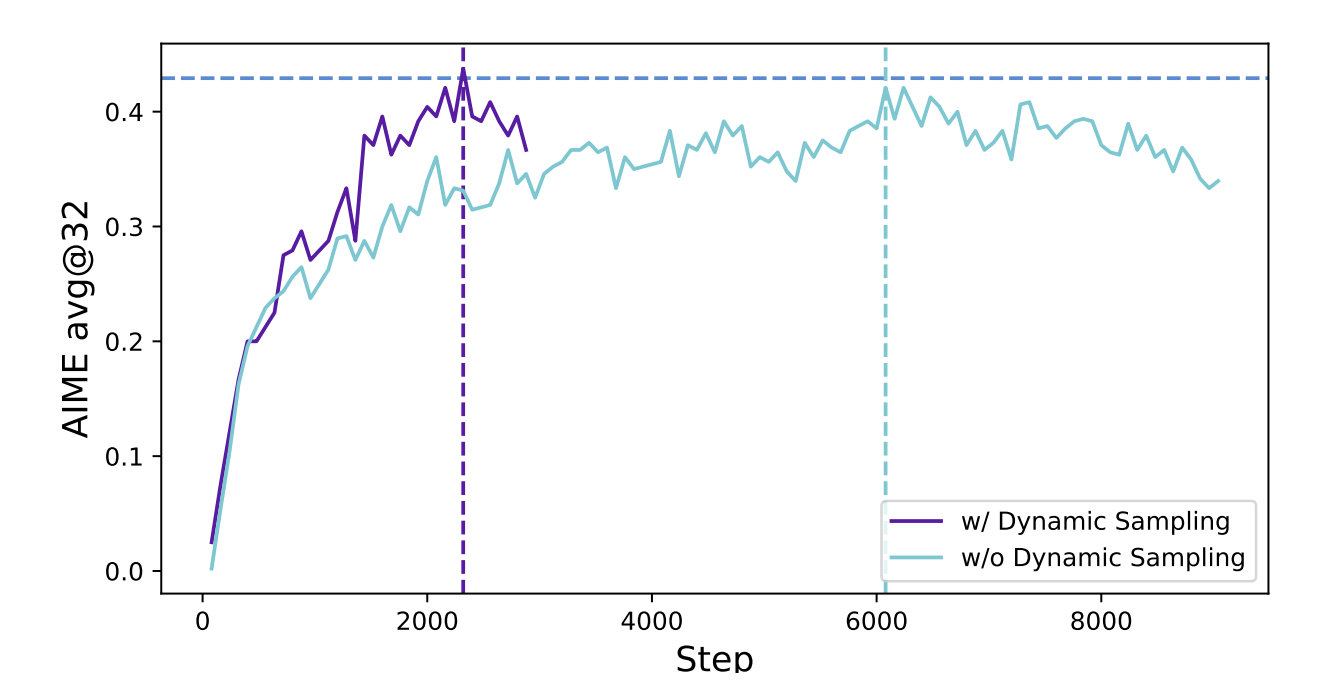
이렇게 샘플을 필터링 하는 방식으로 학습하여 더 빠르게 동일한 성능에 도달하는 것 확인
3.3 Rebalancing Act: Token-Level Policy Gradient Loss
-
제안 : Token 단위의 loss 계산
\[\left[ \frac{1}{G} \sum_{i=1}^G \sum_{t=1}^{|o_i|} \min\Big( r_{i,t}(\theta)\hat A_{i,t}, \text{clip}\big( r_{i,t}(\theta), 1-\varepsilon_{\text{low}}, 1+\varepsilon_{\text{high}} \big)\hat A_{i,t} \Big) \right]\]
예시
토큰 평균 안 냄
$L = \frac{1}{2} \left( \sum_{t=1}^{10} 1 + \sum_{t=1}^{100} 1 \right)$
즉,
- 샘플 A → 10번 기여
- 샘플 B → 100번 기여
- 배경
- 기존 GRPO 알고리즘은 sample 단위로 loss를 계산함
-
각 샘플 내에서 token 단위로 loss를 먼저 평균내고, sample 간 loss를 다시 평균내는 방식
\[\left[\frac{1}{G}\sum_{i=1}^{G}\frac{1}{|o_i|}\sum_{t=1}^{|o_i|}\min\left(r_{i,t}(\theta)\hat A_{i,t},\operatorname{clip}\left(r_{i,t}(\theta),1-\varepsilon,1+\varepsilon\right)\hat A_{i,t}\right)-\beta D_{\mathrm{KL}}(\pi_\theta\|\pi_{\mathrm{ref}})\right]\] - 이런 접근 방법은 모든 샘플이 동일한 가중치를 갖기 때문에 long-CoT에서는 loss 반영 비중이 상대적으로 작아질 수 있음
- 이로 인해, 좋은 long reasoning 을 제대로 못 배우고 나쁜 long samples을 제대로 못 금지함
예시
Sample-level loss: 각 샘플 안에서 평균을 먼저 냄.
샘플 A
$L_A = \frac{1}{10} \sum_{t=1}^{10} 1 = 1$
샘플 B
$L_B = \frac{1}{100} \sum_{t=1}^{100} 1 = 1$
최종 loss:
$\frac{1}{2}(L_A + L_B) = 1$
→ 두 샘플이 동일 weight
→ 만약 샘플 B가 의미없는 반복 패턴으로 채워진 응답이어도 loss 에 반영할 수 없음
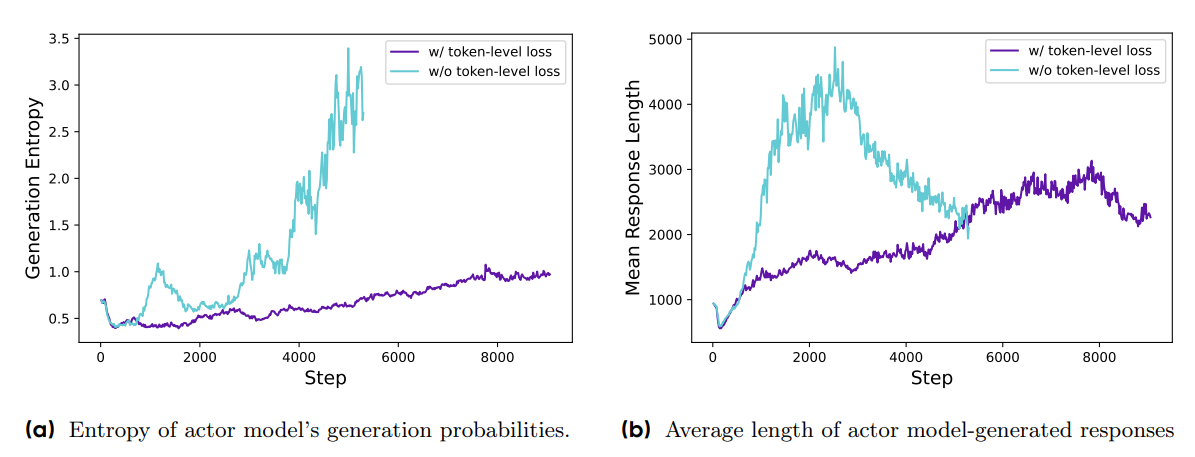
- sample level loss 의 경우 entropy와 응답 길이가 비정상적으로 증가하는 결과를 확인함
3.4 Hide and Seek: Overlong Reward Shaping
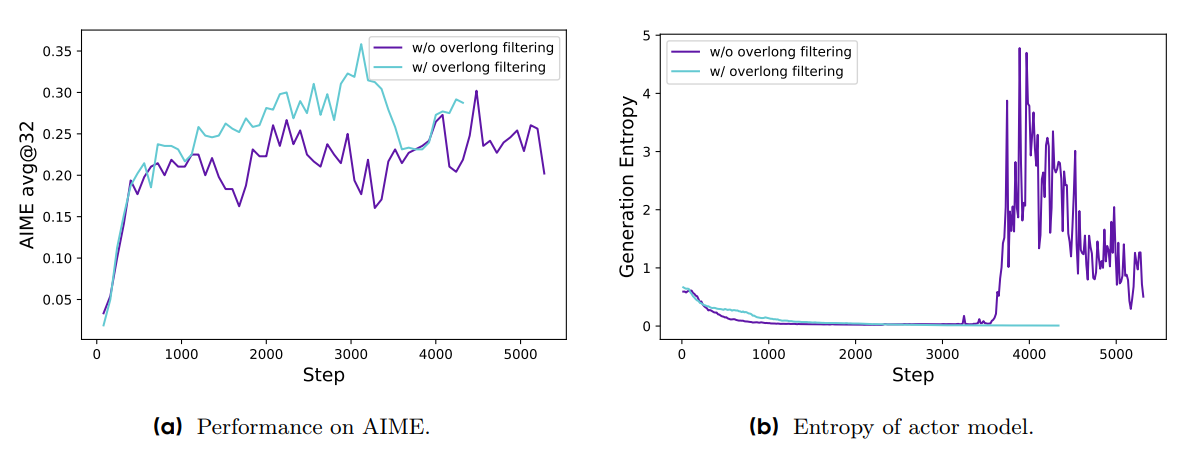
- 제안 : Soft overlong Punishment. 잘린 샘플에 대한 보상 구조
- 길이에 따른 패널티 구간을 정의하여, 응답이 길어질 수록 큰 패널티를 받도록 함
- 배경
- RL training 에서는 일반적으로 최대 생성 길이를 설정하고, 초과하는 샘플은 잘라냄
- 만약 잘린 샘플에 부적절한 reward shaping 을 적용한 경우, reward noise가 발생하여 학습에 문제가 될 수 있음 → 논리적으로 타당한 추론 과정에 대한 적절한 보상

3.5 Dataset Transformation
- web, official competition 홈페이지에서 데이터 수집함
- 수학 데이터셋의 정답은 숫자, 수식, 표현식 등 다양한 형태로 제공되어 이를 모두 처리할 수 있는 규칙 설계는 쉽지 않음
- 논문에서는 정답을 정수 형태로 변환하여 사용
- 예를 들어, $\frac{a+\sqrt{b}}{c}$ 형태라면 llm으로 문제를 수정해서 정답이 $a+b+c$ 형태가 되도록 함
- 총 17k 의 프롬프트로 구성된 DAPO-Math-17K dataset 구축

4. Experiments
4.1 Training Details
- mathematical tasks 에 적용
- 학습은 verl framework를 사용함
- Overlong Reward Shaping 최대 길이 16,383 토큰. soft punishment 캐시로 4,096 토큰 할당
- clip range : (0.2, 0.28)
- AIME 평가에서는 세트를 32회 반복 실행하고, avg 32를 사용
4.2 Main Results
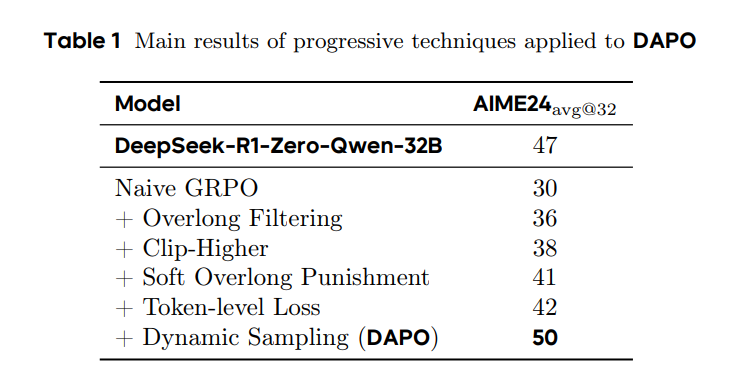
- DeepSeek-R1-Zero-Qwen-32B가 요구한 학습 스텝의 50%만으로 달성
-
각 기법의 성능 향상 정도
-
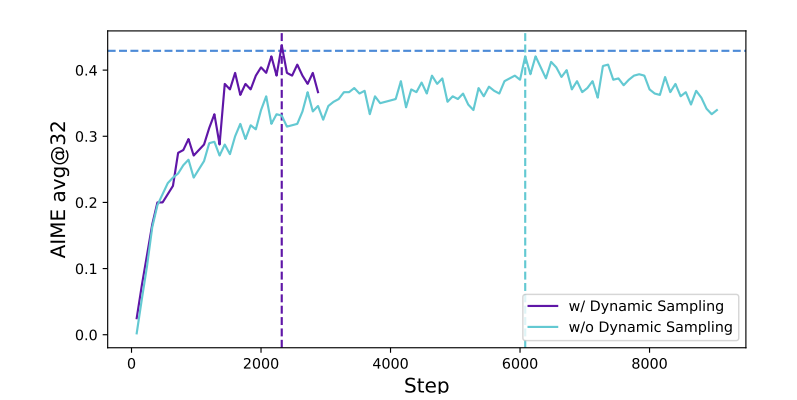
Dynamic sampling 은 zero-gradient 데이터를 제거하여 더 많은 샘플링이 필요하지만 전체 학습 시간에 큰 영향을 주지 않음
4.3 Case Study
- 학습 과정 중 actor 모델의 reasoning patterns이 시간에 따라 동적으로 변화한다는 점을 발견함
- 구체적으로 기존 유효한 reasoning pattern 강화뿐만 아니라 새로운 reasoning pattenrs도 만들어냄
- 아래 예시처럼 모델이 back tracking 행동을 보이기 시작하는 것을 발견함
