![[논문 리뷰] In-Context Reinforcement Learning via Communicative World Models](/assets/img/250911/image.png)
[논문 리뷰] In-Context Reinforcement Learning via Communicative World Models
작성자: 민예린
논문 정보
제목: In-Context Reinforcement Learning via Communicative World Models
저자: Fernando Martinez-Lopez, Tao Li, Yingdong Lu, Juntao Chen.
학회: Preprint
Summary
| 내용 | 링크 |
|---|---|
| 논문 | https://arxiv.org/pdf/2508.06659 |
| 코드 | https://github.com/fernando-ml/CORAL |
요약
- Representation과 Policy 학습을 분리한 CORAL (Communicative Representation for Adaptive RL)을 제안
- [Representation] IA (Information Agent) : 다양한 tasks distribution을 사전 학습한 world model
- [Policy] CA (Control Agent): IA의 context를 이용해 action을 예측함$\pi(⋅ \ \mid \ observation, \ message)$
- 환경을 잘 표현하는 IA 활용 이점
- CA가 샘플 효율성이 올라감
- unseen sparse reward environments에 대해서도 zero-shot adaptation 성능이 올라감
0. Related Work
In-Context Reinforcement Learning
- In-context learning : context 내 몇 가지 예시만 보고도 모델 가중치 변경 없이 새로운 예시에 적응(adapt) 할 수 있는 방법
- ICRL 에서 말하는 few-shot adaptation의 개념은, 과거에 등장했던 gradient free meta learning 와도 연관이 있음
- 당시 historical interaction으로부터 task-specific hidden context를 뽑아내기 위해 RNN + RL 을 했었음 (여러 task 를 푸는 일반화된 RL 모델을 학습하기 위한 방법)
- 이후 Transformer 가 등장하면서 ICRL이 더 발전하기 시작했는데, 사전 학습은 in-context adaptation을 위한 핵심 단계로 볼 수 있음
-
기존 연구
(1) (Self) Supervised Pre-training : Offline 데이터를 이용하여 Pre-training
-> 일반화 개선에 도움이 되지만 여전히 out of distribution 문제가 남아 있고, offline data 품질에 크게 의존
(2) Reinforcement Pre-training : 다양한 환경과의 Online Interaction을 통해 Pre-training
- CORAL 은 Reinforcement Pre-training 범주에 속하며, 정책이 고정되어 있는 offline data 뿐 아니라 online interaction을 통해서도 학습하는 hybrid of supervised-pre-training 방식을 채택함 (IA와 CA)
-
World Models
- World model : 현실 세계의 물리적 법칙, 공간, 시간, 상호작용 등을 이해하고 시뮬레이션 할 수 있도록 구축된 모델의 일종임
- 예를 들어, 고양이가 공을 굴리면 공이 어떻게 움직일지, 유리컵을 떨어뜨리면 어떻게 될지 등 세상의 변화를 예측하는 것을 목표로 함
-
RL 에서는 일반적으로 아래와 같이 사용됨
(1) 환경으로부터 받은 observation을 latent vector z로 변환하고,
(2) latent vector z와 action을 입력으로 next latent vector z’을 예측하는 역할로 많이 사용됨
(이상적으로는 환경을 완전 대체할 수도 있음)
- 뒤에 MCTS 같은 controller를 붙이면 rollout도 가능함
- 최근 생성 모델이나 transformer 의 발전과 함께 성능이 같이 많이 올라감
- CORAL 에서는 world 모델의 개념을 환경의 dynamics를 이해하고 이를 추가 정보로 agent에게 제공함
- 가장 관련 깊은 연구로 communication-based decentralized WMs[1] 가 있는데, multi-agent RL task에서 각 agent에 WM을 장착하고 각자의 미래 예측 정보를 communication 하는 방식을 제안함 (-> 추가적인 정보로)
- CORAL은 single agent RL이고 추가 정보의 관점으로 WM을 사용한다는 점이 유사함
1. Introduction
Motivation
- 최소한의 개입으로 다양한 tasks를 해결할 수 있는 generalist agent를 만드는 것이 목적
- 일반화를 위해 (1) In-Context RL (ICRL) 과 (2) World Model (WM) 에 많은 노력이 집중되고 있음
- ICRL의 큰 장점은 meta RL 처럼 policy model update에 의존하지 않고 context 를 기반으로 zero-shot 추론이 가능하다는 것인데, 대신 기본적인 task dynamics를 이해하지는 못 한다는 한계가 있음 (환경에 대한 이해도가 떨어짐)
- 반대로 World model은 환경의 dynamics와 reward feedback을 구조적으로 이해하도록 학습 시키기 때문에 unseen state에 대해서도 환경이 어떻게 변할지 예측할 수 있음
제안
- 각각의 장점을 이용하고 한계점들을 극복하기 위해 representation learning / policy learning 을 분리한 구조의 CORAL (Communicative Representation for Adaptive RL) 프레임워크를 제안함
- 이때 CORAL’s novelty는 IA가 message를 생성할 때 아래 세 가지 측면을 고려한다는 것임
- dynamics awareness : 메시지 안에는 환경의 미래 변화에 대한 예측 정보가 들어 있어야 함
- temporal coherence : 같은 상황(동일한 context)에서 연속적으로 생성되는 message들은 비슷해야 함
- in-context communication effectiveness : message를 받아서 행동을 선택했을 때는 message가 없을 때보다 더 높은 보상을 받아야 함(메세지가 실제로 policy 성능에 도움 된다는 걸 보장하는 조건)
Contribution
- Formulation : Single-agent ICRL 문제를 world model(Information Agent) 가 학습한 dynamics를 Control Agent에 전달하는 communication 문제로 재정의함
- Hybrid Training : IA와 CA는 서로 다른 목표를 갖기 때문에 분리해 학습함
- IA : dynamics 인식, 시간적 일관성, 의사소통의 효과성을 목표로 하는 3가지 loss function 으로 self-supervised learning 진행
- CA : RL Pre-training을 위해 PPO 알고리즘 사용
- Empirical Validation : Sparse-reward environment 를 대상으로 실험 진행하였고, 샘플 효율성을 크게 개선하며 zero-shot generalization이 가능함을 입증
2. Methodology
Information Agent (IA)
-
3가지 목표의 Self-supervised loss function
\[L(ϕ)=λ _{Dyn} L_{Dyn} (ϕ)+λ_{Coh}L_{Coh}(ϕ)+λ_{Causal}L_{Causal}(ϕ)\]
Dynamics awareness (첫 번째 항) : CA의 행동 결과를 예측하도록 학습 시켜 dynamics를 배우도록 함
- 실제 $o,r,d$와 $\widehat{o}, \widehat{r},\widehat{d}$의 차이를 학습함 (o : 관측, r : 보상, d : 종료 여부 )
- 예측은 $f^{Dyn}_{\phi}(m_t, a_t)$ 에서 생성함
- 관측과 보상은 연속 값이기 때문에 MSE 사용, 종료 확률은 확률 값이라 binary cross entropy 를 사용함
Temporal coherence (두 번째 항) : 시간적 일관성을 높이기 위해 현재 message 기반 다음 message 를 예측하도록 학습함
- 미래 메세지를 예측할 수 있는 representation이 되도록 유도함
Causal Influence (세 번째 항) : 효과적인 communication을 유도하기 위해 정보 이론적 목표를 도입
-
ICE (Instantaneous Causal Effect) : 메세지가 있을 때와 없을 때의 KL divergence를 표현
\[ICE_t=D_{KL}[π_θ(⋅∣o_t,0) ∥ π_θ(⋅∣o_t,m_t)]\] -
Hybrid utility signal $U$ : 장기적인 지표 GAE $A$와 CA의 value estimate의 즉각적 변화인 $V$를 결합
- U는 constant로 취급되어, gradient가 KL term을 통해서만 흐르도록 함
- 즉각적인 / 장기적인 지표를 사용하여 지표가 좋을 때만 ICE에 가중하여 사용 (음수면 0으로 사용)
Control Agent (CA)
- PPO 방법을 사용하여 학습
- IA의 message 를 활용
- IA와 joint learning 함
Multi-Environment Training for Generalization
- CORAL 의 목적을 다시 리마인드 하면, single task가 아닌 여러 tasks에 적용 가능한 일반화 모델을 만드는 것을 목표로 함
- 그렇기 때문에 $T={env_1, env_2, …, env_k}$ 다양한 환경에서 학습을 진행함
- 대규모 분산 학습을 위한 JAX 사용
- rollout 시작 시 랜덤한 과제 하나를 선택 (each parallel environment instance)
- 업데이트 배치에 다양한 환경 데이터가 포함되어 특정 환경이 아닌 환경 전반에 걸쳐 IA가 학습됨
Deployment for Rapid In-Context Adaptation
- 배포 단계에서는 IA의 $\phi$는 고정
3. Experimental Results
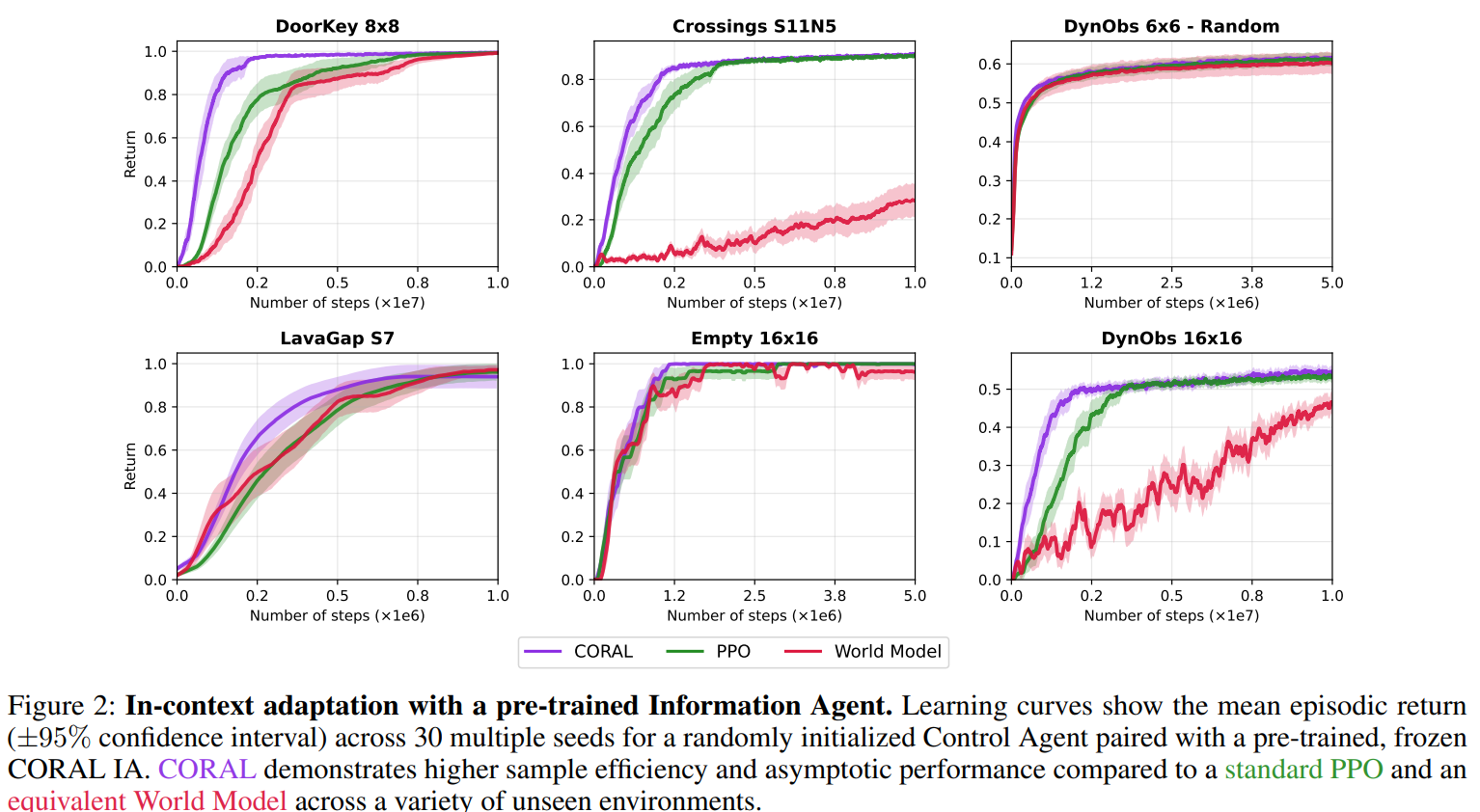
Accelerated Control Learning via In-Context Communication
- CORAL이 PPO, World Model 보다 빠르게 새 환경에 적응
- PPO 와 비교 : message의 학습 효율성
- World Model과 비교 : 새로운 환경에서의 일반화 성능
- 어려운 환경인 Dynamic Obstacles 16x16의 경우 CORAL의 빠른 적응이 더 잘 보임
-
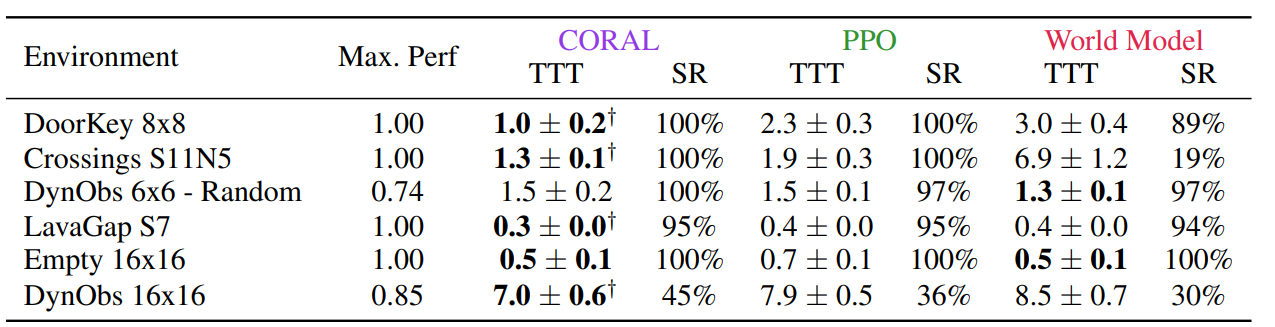
샘플 효율성 평가를 위해 TTT(Time to Threshold) 분석을 수행, 각 환경에서 도달한 최대 성능의 90% 도달을 위해 필요한 평균 스텝 수를 측정함
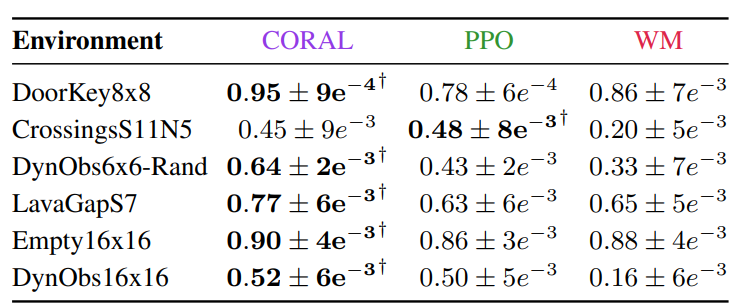
Integrated In-Context Communication and Control for Zero-Shot Generalization
-
Zero-Shot 성능도 PPO, WM에 비교하여 더 높음
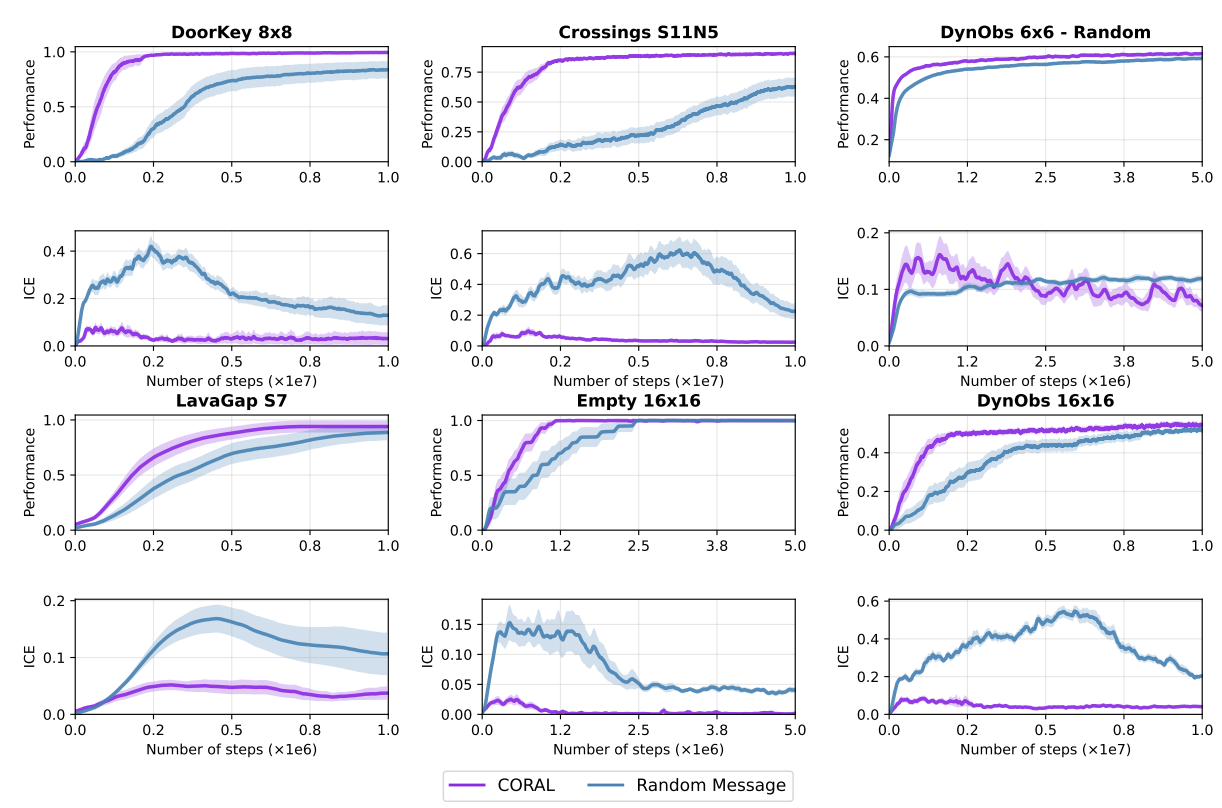
Analysis of the Emergent Communicative Protocol
- Communication에 의한 성능 향상이 발생하는지 확인
- ICE 값은 메세지 유무에 따른 정책 분포 차이를 의미함 → 값이 크면 policy 차이가 있다
- CORAL의 경우 초기엔 메세지의 ICE가 크다가 후반 학습이 안정되어 가면서 ICE가 작아짐 → 초반엔 policy 에 큰 영향을 주다가 학습이 안정화되면 confirm 수준으로 값이 안정화됨
- 랜덤은 노이즈라서 ICE를 키울 수는 있으나 실제 performance와 연관이 있어 보이지는 않음
Reference
[1] Toledo, E.; and Prorok, A. 2024. CoDreamer: Communication-Based Decentralised World Models. In Coordination and Cooperation for Multi-Agent Reinforcement Learning Methods Workshop.