![[논문 리뷰] Diffusion Guidance Is a Controllable Policy Improvement Operator](/assets/img/250619/image_2.png)
[논문 리뷰] Diffusion Guidance Is a Controllable Policy Improvement Operator
작성자: 민예린
논문 정보
제목: Diffusion Guidance Is a Controllable Policy Improvement Operator
저자: Kevin Frans, Seohong Park, Pieter Abbeel, Sergey Levine, UC Berkeley.
학회: Preprint
요약
- 배경 : 데이터의 성능을 넘어서는 강화학습 모델 학습
- 기존 강화학습 방법을 사용하면 데이터 보다 좋은 성능을 내는 모델을 만드는 게 꽤 까다로움
- 방법
- generative modeling 기법을 활용
- generative modeling은 학습이 간단하고 scalable 하다는 것이 입증되어 있음
- policy improvement와 diffusion model의 guidance 의 연결 관계를 찾고 장점을 결합
- generative modeling 기법을 활용
- 제안
- CFGRL (Classifier-Free Guidance RL) 프레임워크를 제안함
- 학습은 지도학습처럼 단순하면서, 데이터의 정책보다 더 나은 정책으로 향상 가능
- value function을 명시적으로 학습하지 않고도 작동이 가능
- 단순한 지도 학습 방식들(e.g., goal-conditioned behavioral cloning) 보다 더 일반화하고 높은 optimality 를 가질 수 있음
- CFGRL (Classifier-Free Guidance RL) 프레임워크를 제안함
- Limitation
- 이 방법은 완전한 RL 절차를 대체하려는 목적이 아님
- value function은 이미 주어진 것으로 가정하며, 이를 어떻게 학습할지는 논문에서 다루고 있지 않음
- 기존의 지도 학습 방식을 CFGRL로 대체하여 단순성과 안정성을 유지함
- 이 방법은 완전한 RL 절차를 대체하려는 목적이 아님
Introduction
- 외부에서 수집한 (학습 과정 중에 수집한 것이 아닌) 데이터셋을 사용해서 강화학습을 진행하는 것은 꽤 쉽지 않음
- Is Value Learning Really the Main Bottleneck in Offline RL? 논문처럼!
→ 외 다양한 Offline RL 논문들에서 Offline to Online 의 불안정한 학습에 대해 얘기하고 있음
- 반면, generative modeling 기법들은 behavior cloning 등에서 많이 활용되고 그 효과가 입증되어 있음
- (지도 학습 프로세스에 생성 기법들을 적용하면 성능이 잘 나오는 게 추가적인 설명 없이도 충분히 납득 가능하긴 함)
그렇다면, generative modeling tools를 사용해서 RL에 적용해볼 수 있지 않을까?
강화학습 방법론
- 장점
- data 에(buffer) 있는 성능을 ‘최적화’ 하려는 개념 존재
- 특히 sub-optimal data를 이용해 학습해도 더 좋은 성능을 낼 가능성이 존재함
- 단점
- hyperparameter에 민감하고 성능이 불안정함
- larger tasks로 확장하는데 어려움이 있음
생성 모델링 (behavior cloning 관점)
- 장점
- diffusion, flow-matching 같은 안정적인 method를 사용해볼 수 있음
- 단점
- 데이터의 퀄리티가 성능을 결정함
그렇다면 두 방법들의 장점을 결합한 프레임워크를 만들어보자!
제안
- diffusion model guidance와 RL의 policy improvement 사이의 이론적 연결을 제안
- 위 연결을 바탕으로 Offline RL과 goal-conditioned behavioral cloning 모두에서 안정적으로 정책을 학습할 수 있는 간단한 실용 알고리즘 개발
Related Work
Offline RL
- Offline RL은 Offline dataset 을 이용해 강화학습을 진행
- 환경과 interaction & exploration 하면서 학습하지 않고, 수집된 데이터셋으로 보상을 최대화하는 정책 학습을 목표로 함
- Offline RL의 challenge는, 모델이 낯선 상황에 대해 부정확하게 예측하거나, 과도한 자신감을 가지는 것임
- 이러한 문제를 해결하기 위해 주로 value learning (Q-value 보정) 이나 policy extraction 관점에서 실험들을 진행
- 본 연구는 단순하게 지도학습의 목표를 강조한다는 점에서 weighted regression이나 return-conditioned behavior cloning 과 밀접한 관련이 있음
- regularization과 policy improvement의 균형을 diffusion model의 guidance 라는 관점으로 재구성하고, 이 균형을 테스트 시점에서 직접 조절할 수 있는 방법을 제시함
Diffusion and flow policies for RL
Classifier Free Guidance Diffusion
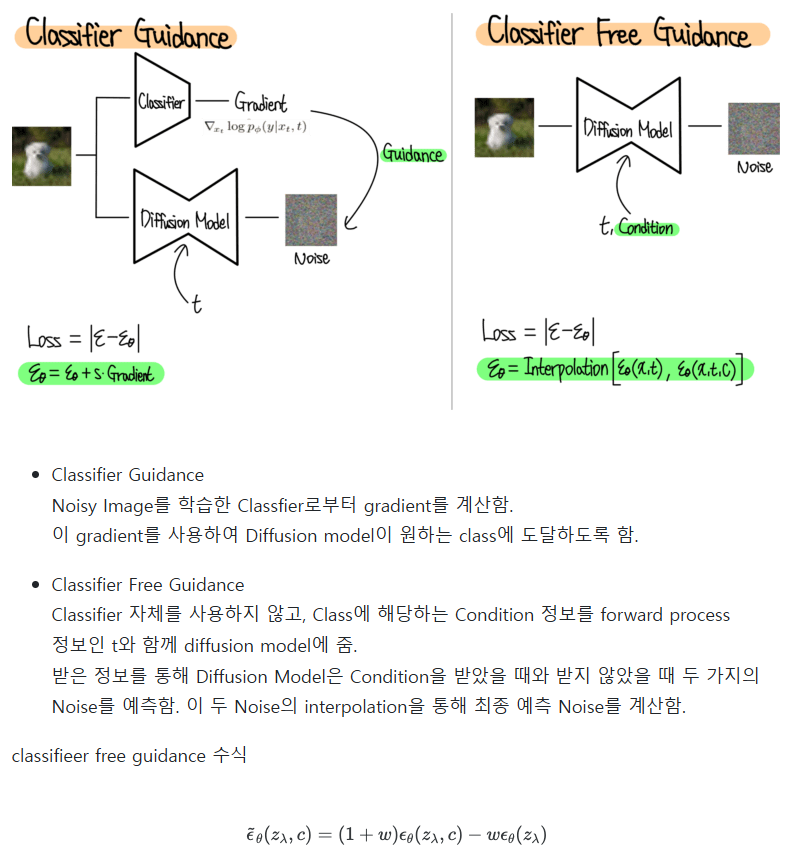
](/assets/img/250619/image%201.png)
- diffusion model이나 flow model의 표현력을 활용하여 RL의 성능을 높이려는 노력들이 있었음
- 이런 학습 방법들의 challeng는 Q-function으로부터 diffusion policy 를 어떻게 효과적으로 추출하는가 임
- 기존 연구들은 이에 대한 해결책으로 weighted regression, reparametrized gradients, rejection sampling 등의 기법들을 제안해옴
- 본 연구는 이런 정책 추출 방식으로서 classifier-free guidance를 도입함
- 이 방식은 기존 방식에 대해 여러 이점을 가지는데, rejection sampling 처럼 비용이 많이 드는 샘플링 후 필터링 절차가 필요없고 reparametrized 방법들처럼 시간 순서에 따른 backpropagation이 필요없다는 이점이 있음
- 또한 명시적인 value function을 사용하지 않음
Diffusion guidance is a controllable policy improvement operator
diffusion의 classifier-free guidance와 강화학습의 policy improvement 의 연관성을 규명
- 정책의 개선 정도를 학습 시점이 아니라 테스트 시점에서 제어할 수 있게 해줌
- Q-function을 반드시 요구하지는 않기 때문에 goal-conditioned behavioral cloning 같은 기법을 대체하거나 추가 성능 향상에 사용할 수 있음
Preliminaries
Product policies
-
정책을 reference policy와 optimality function f ( ℝ → ℝ) 로 파라미터화 함
$\pi(a \mid s) \propto \hat{\pi}(a \mid s) \cdot f(A(s, a))$
- 위와 같이 곱셈 구조로 만든 것은, reference policy 에 확률적인 조정을 가하여 더 나은 정책을 만들기 위해서임
- diffusion guidance 는 이러한 분포에서 샘플링하기 적합함
- A : advantage function (해당 행동이 평균보다 얼마나 좋은지 나타냄)
Product policy as Policy improvement operators
Remark 1 (Improvement of product policies)
- 만약 f가 advantage A에 대해 non-negative monotonically increasing function이라면 해당 곱 형태의 policy는 reference policy 보다 성능이 향상됨
- 적절하게 가중된 product policy 에서 샘플링할 수 있다면 결과 policy는 reference policy 보다 더 높은 기대 보상을 달성함
Remark 2 (Further improvement via attenuation) $\text{Let } 0 \leq w_1 < w_2 \text{ be real numbers, and} \ \pi_{w_i}(a \mid s) \propto \hat{\pi}(a \mid s) \cdot f(A(s, a))^{w_i}, \ \text{for } i = 1, 2. \ \text{Then, } \pi_{w_2}(a \mid s) \text{ is an improvement over } \pi_{w_1}(a \mid s).$
-
optimality 함수를 통해 개선의 정도를 제어할 수 있음
$\pi(a \mid s) \propto \hat{\pi}(a \mid s) \cdot f(A(s, a))^w$
- 이를 위해 지수 형태의 optimality를 사용한 product policy를 고려함
- f가 크면 좋은 행동일 확률을 크게 반영, 작으면 적게 반영
Remark 3 (KL-regularized reward-maximization results in product policies) $\pi(a \mid s) \propto \hat{\pi}(a \mid s) \cdot \exp\left( \frac{A(s, a)}{\beta} \right)$
- 지수를 크게 하면 advantage 기준으로 더 나은 정책이 되지만, 결과 policy 가 reference policy 와 차이가 커지게 됨
- 따라서 과도한 조정은 오히려 성능 저하로 이어짐
- policy와 reference policy 사이의 균형을 유지하기 위한 수식은 KL-regularized RL objective 로 설명될 수 있음 (TRPO의 trust region 처럼)
Composing factors via diffusion guidance
diffusion guidance 추가 방법
-
먼저 optimality function을 binary random variable $o∈\lbrace ∅,0,1 \rbrace$ 로 간주하고 그 확률을 함수 $f$로 정의함
$p(o \mid s, a) = \frac{f(A(s, a))}{Z(s)}, \ \text{where} \ Z(s) = ∫f(A(s,a’))da′ \ \ \text{is a state-dependent normalization factor}$
- Z(s) 는 상태 s에 따른 정규화 상수로, 모든 가능한 행동 a’에 대해 $f$를 적분한 것
-
결과적으로 product policy는 아래와 같이 다시 표현됨
$\pi(a \mid s) \propto \hat{\pi}(a \mid s) \cdot p(o \mid s, a)$
Recall Diffusion models implicitly model a distribution by learning its normalized score function, i.e., the gradient of log-likelihood under that distribution
- Score function : 확률 분포의 log-likelihood에 대한 gradient $∇_alogp(a)$
score function은 product distributions 에서는 덧셈으로 결합된다는 유용한 성질이 있음
-
$p(a)=p_1(a)⋅p_2(a)$
→ log 취함 : $logp(a)=logp_1(a)+logp_2(a)$
→ gradient 취함 : $∇_alogp(a)=∇_alogp_1(a)+∇_alogp_2(a)$
-
따라서 product policy의 score는 아래처럼 표현될 수 있음
$∇_alogπ(a∣s)=∇alog\hat π(a∣s)+∇_alogp(o∣s,a)$
Avoiding an explicit optimality predictor
- 하지만 실제로 $p(o \mid s,a)$를 학습하려면 Z(s)의 계산이 복잡할 수 있음
- 따라서 classifier-free guidance 의 아이디어를 사용하여 optimality의 분포를 Bayes 법칙으로 바꿔주면 조건부 정책의 socre로 바꿀 수 있음
- $∇_alogπ(a∣s)=∇_alog\hatπ(a∣s)+(∇_alog\hatπ(a∣s,o)−∇_alog\hatπ(a∣s))$
-
Bayes 법칙 : $p(A∣B)=\frac{p(B∣A)⋅p(A)}{p(B)}$
→ $p(o∣s,a)=\frac{\hatπ(a∣s,o)⋅p(o∣s)}{\hatπ(a∣s)}$
→ log 취함 : $logp(o∣s,a)=log\hatπ(a∣s,o) +logp(o∣s)−log\hatπ(a∣s)$
→ gradient : $∇_alogp(o∣s,a)=∇_alog\hatπ(a∣s,o)−∇_alog\hatπ(a∣s)$
→ 위 Racall 쪽 수식에 대입하면 아래와 같은 최종 형태가 됨
$∇_alogπ(a∣s)=∇_alog\hatπ(a∣s)+(∇_alog\hatπ(a∣s,o)−∇_alog\hatπ(a∣s))$
-
- $∇_alogπ(a∣s)=∇_alog\hatπ(a∣s)+(∇_alog\hatπ(a∣s,o)−∇_alog\hatπ(a∣s))$
Guidance controls the attenuation of optimality
-
guidance weight $w$ 도입
$∇_alogπ(a∣s)=∇_alog\hatπ(a∣s)+w(∇_alog\hatπ(a∣s,o)−∇_alog\hatπ(a∣s))$
Training and sampling with CFGRL
- 학습을 단순하게 하기 위해 flow-matching 프레임워크를 사용하여 아래 손실 함수로 학습됨
- flow matching 은 score 대신 velocity를 예측하지만 score와 유사한 성질을 가진다고 함
$L(θ)=E_{s,a∼D}[\lVert v_θ(a_t,t,s,o)−(a−a_0) \rVert^2] \ \text{where} \ a_t=(1−t)a_0+t_a$
CFGRL improves over weighted policy extraction in offline RL
-
Offline RL 에서 Advantage-Weighted Regression (AWR) 방식을 사용
$J_{AWR}(θ)=E_{(s,a)∼D}[logπ_θ(a∣s)⋅exp(\frac{A(s,a)}{β})]$
-
위 방식은 가중치가 너무 쏠리는 문제 때문에 일부 샘플이 지나치게 강조되는 문제가 있음
CFGRL 도입

-
단순한 기준으로 optimality 를 정의하고 위에서 설명한 conditional diffusion model 방식으로 학습
$o =\begin{cases}1 & \text{if } A(s, a) \geq 0 \\ 0 & \text{if } A(s, a) < 0\end{cases}$
- AWR vs CFGRL
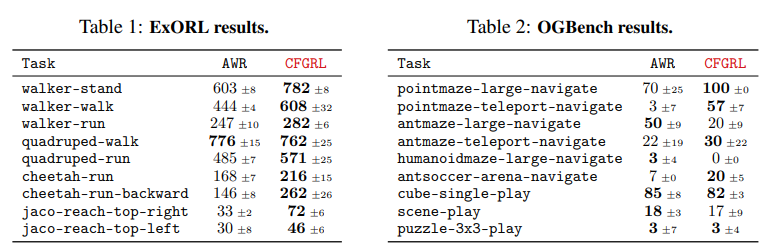
CFGRL unlocks hidden gains in goal-conditioned behavioral cloning
- CFGRL 프레임워크는 일반적인 구조이지만, 특히 goal-conditioned RL 에서 매력적으로 작용함
- 이유 : 학습된 value estimator 없이 단순(하지만 조잡한)한 근사 방식 사용 사능
- Key insight는 base policy 에 대해 한 단계의 policy improvement 를 가능하게 해준다는 점임
- 따라서 목표 g에 대한 guidance를 통해 기존보다 더 나은 정책을 얻을 수 있음
$π(a \mid s, g) = \frac{π̂(a \mid s) p^γ(g \mid s, a)}{p^γ(g \mid s)} ∝ π̂(a \mid s) Q̂(s, a, g)$
→ $∇_alog \hatπ(a \mid s) + w (∇_a log π(a \mid s, g) − ∇_a log \hatπ(a \mid s))$
Experimental results
Task
- 17 state-based & 7 pixel based goal-conditioned RL tasks (from OGBench task)
- 휴머노이드, 미로 탐색, 연속적인 물체 조작, 조합 퍼즐 해결 등
Methods
- BC, Flow BC
- GCBC (goal conditioned BC), Flow GCBC
- HCFGRL (Hierarchical CFGRL)
→ Flow OO은 flow policy 로 학습
→ Flow BC는 guidance weight 가 0인 CFGRL, Flow GCBC는 guidance weight가 1인 CFGRL과 동일
Results
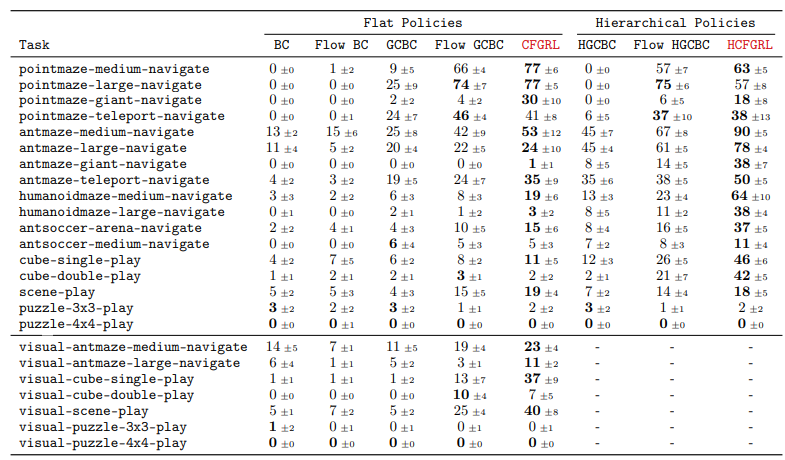
- weight에 따른 성능 변화 : w가 증가함에 따라 성능이 향상되는 경향 확인
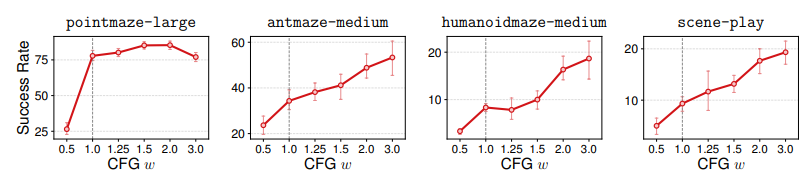
Discussion and Conclusion
- policy improvement와 diffusion model의 guidance 의 연결 관계를 찾고 장점을 결합한 프레임워크를 소개함
Limitations
- 이 방법은 완전한 RL 절차를 대체하려는 목적이 아님
- value function은 이미 주어진 것으로 가정하며, 이를 어떻게 학습할지는 논문에서 다루고 있지 않음
- 기존의 지도 학습 방식을 CFGRL로 대체하여 단순성과 안정성을 유지함
- 그러나 더 복잡한 방식의 기법이나 online RL, policy gradient 방법 등을 결합하면 더 강력한 성능을 얻을 수도 있음
- RL 이론과 생성 모델링의 연결의 시작, 향후 연구를 위한 출발점으로 생각
References
- [5] Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control. ArXiv, abs/2410.24164, 2024.
- [13] Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. In Robotics: Science and Systems (RSS), 2023.
- [36] Michael Janner, Yilun Du, Joshua B. Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis. In International Conference on Machine Learning (ICML), 2022.